SequoiaDB 简介 
安装部署
数据库实例
分布式引擎
SAC 管控中心
参考手册
常见问题及解答(FAQ)
版本信息
SequoiaDB 巨杉数据库作为一款分布式文档型数据库,主要面向实时处理、多模型数据处理等多种业务场景,在包括银行、证券、保险、电信、政府、互联网等行业具有广泛的应用场景
近年来,随着 IT 技术与大数据的不断发展,越来越多的企业将数据作为自身宝贵的资产进行长期保留。同时,微服务与分布式技术的不断发展,使得联机应用程序不再使用“烟囱式”方式构建,而是需要由众多原子服务组件在一个数据池中进行灵活的数据访问。这使得一些传统联机应用程序的历史数据包袱越来越重,灵活性大幅度下降,导致最终数据库不堪重负、 应用整体性能低下。另一方面,随着大数据需求的不断增加,曾经已经归档的数据需要重新在线以满足在线化、实时化使用、查询和分析等等要求,这就要求将原有庞大的离线数据进行“在线化”与“服务化”。这些需求使得数据中台系统成为各大企业 IT 建设与投入的方向。
数据中台主要提供全量数据的实时在线服务,同时提供对海量数据进行采集、计算、存储、加工以及基于全量数据的数据价值发掘和数据科学工程等。在过去,银行等机构的数据管理简单的划分为在线核心以及归档两个部分,随着业务的复杂化以及互联网、移动业务带来的海量数据的增长,数据在治理、挖掘等方面的重要性凸显,因此数据中台就成为了现在金融等大型企业关注的业务重点。SequoiaDB 巨杉数据库提供了企业历史与实时数据的统一纳管平台,激活企业数据核心价值。通过对海量历史与实时数据的采集、计算、存储和加工,数据中台为应用上层多变的业务逻辑与底层稳定的数据结构提供中间层统一的标准与口径,满足企业业务和数据的沉淀,实现生产系统瘦身、历史数据在线化,降低重复建设、减少烟囱式协作的成本,增强企业差异化竞争优势。
数据中台方案并非某一种特殊的技术或产品,而是在企业中提供数据整合并对外提供联机服务的一组数据服务。不同于大数据以面向内部分析统计挖掘为主,数据中台主要面向外部的最终客户,提供高并发低延时的联机类业务支持。数据中台体系可以分为四大部分,包括 ODS 区、贴源数据存储区、数据加工调度区以及对外服务区。
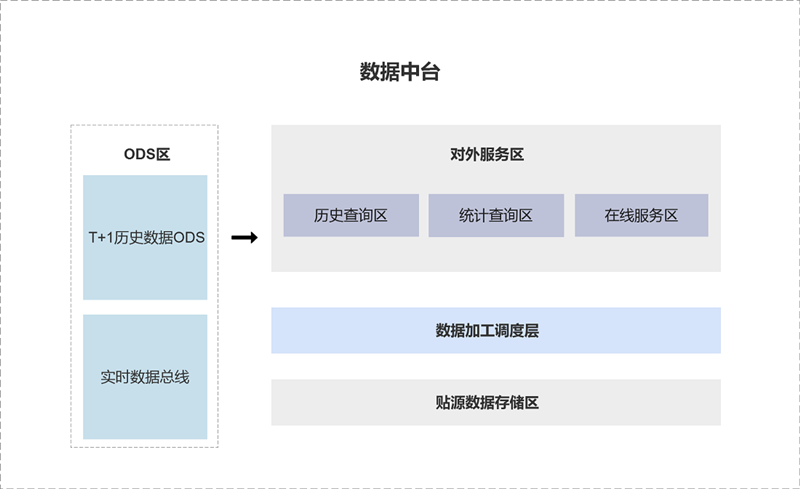
SequoiaDB 巨杉数据库提供的数据中台解决方案的技术特性包括:
基于 SequoiaDB 搭建的数据中台能够提供给客户的价值包括:
基于巨杉数据库构建的数据中台,实现数据融汇贯通,提供联机数据一站式服务,助力企业多业务数据整合,帮助企业跨越底层数据与新业务的鸿沟。目前,已大规模应用于企业生产库瘦身、数据生命周期管理等业务。
SequoiaDB 分布式内容管理解决方案提供了可弹性扩张的非结构化数据存储平台,以及包含批次管理、版本管理、生命周期管理、标签管理、模糊检索、断点续传等丰富的元数据管理机制。
以基于 Spring-Cloud 框架的微服务架构为基础,SequoiaDB 内容管理解决方案通过可插拔组件与可配置流程,允许用户自由定义不同数据存储容器中对象文件的处理方式。譬如,对于合同扫描件类型的业务,系统可以将 OCR 文字识别模块直接加入非结构化文件处理流程,使得所有写入该容器的合同自动进行文字识别处理,并直接支持针对其内容的全文检索能力。
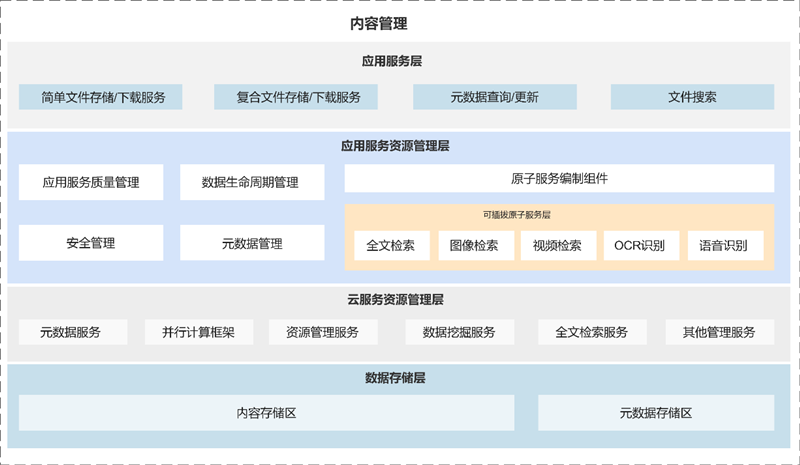
SequoiaDB 巨杉数据库提供的内容管理平台的技术特性包括:
基于 SequoiaDB 搭建的内容管理平台能够提供给客户的价值包括:
基于巨杉数据库的分布式内容管理平台,实现全类型数据的统一管理,主要应用业务包括影像平台、海量音视频管理、非结构化数据治理、双录系统、无纸化系统等。
在当今数字化时代,个性化业务正日益成为企业和组织取得竞争优势的关键因素。传统的客户数据管理系统往往聚焦于收集和存储客户的基本信息,如姓名、地址、电话号码等。但随着数字化时代的到来,客户已经产生了大量的数据,包括浏览记录、购买行为、社交媒体互动等。这些数据蕴含着丰富的信息,通过个性化引擎的分析,可以实现对客户需求和喜好的更深层次理解。而在个性化引擎的背后,数据存储和管理起着至关重要的作用。文档型数据库凭借其灵活的数据存储方式、处理复杂数据结构的能力、灵活的查询和过滤功能,以及扩展性和性能优势,成为处理个性化业务的理想之选。 基于SequoiaDB分布式数据库对结构化、半结构化和非结构化数据的统一管理能力,可实现对多个渠道的各种类型数据的整合,消除数据孤岛,并实现对数据的实时查询,而无需提取、转换或加载等冗余操作,帮助企业构建更高效的个性化业务系统。
全量数据统一管理: 支持跨结构化、半结构化、非结构化的多模数据处理,实现对多渠道来源、多数据类型的整合与统一管理。
业务数据实时查询: 数据从业务发生到提供访问的时延在秒级,可以直接对数据进行复杂的查询,不再需要提取、转换和加载。
业务数据实时查询: 可将数据共享给多个应用程序或系统,有效消除数据孤岛,提升开发和运维效率。
个性化引擎是一种利用先进数据挖掘技术和算法,通过对用户行为、交互历史和偏好等数据的计算挖掘,在实时性上为客户提供定制化的在线体验的解决方案。这些引擎可以在传统客户数据管理系统的基础上建立,也有可能完全取代传统系统,以满足不断增长的个性化需求。个性化业务的应用范围广泛,可以用于金融、政府、汽车、电子商务、社交媒体、智能家居等各个行业。
金融服务: 根据客户的投资偏好、风险承受能力和目标,为他们提供个性化的投资组合、理财建议和财务规划方案。
政府机构: 根据公民的个人情况和所在地区,定制化提供合适的教育、医疗、社会福利等公共服务。
汽车交通: 根据车辆和驾驶者的数据,提供个性化的车联网服务和智能驾驶体验。
电子商务: 可以根据用户的浏览行为、历史交互和兴趣偏好,实时推荐与其兴趣相关的产品和服务。
随着数字化业务的兴起,每个行业都面临着新的挑战。Web、移动、社交、人工智能和物联网应用程序的普及,推动了新一轮的数据爆发。基于SequoiaDB分布式文档型数据库的海量数据横向扩展能力,企业可以将只读查询业务分流到其他节点上,从而减轻主机的负载,实现主机下移。主机下移是一项复杂的技术工程,可以有效减轻主机的负载并提高整体系统性能,提升高并发的查询能力,为架构改造提供增值。从而协助企业降本增效,有效适应业务的高速化发展和数据结构的多样性,应对数字化转型需求。

高并发查询: 提供高并发访问,及在结构化及半结构化数据上建立索引的能力,以支持面向终端业务海量的实时并发性能要求。
灵活扩展: 存储层资源池化,支持在线水平弹性扩缩容,通过分流只读查询业务,降低主机负载。
高效开发: 灵活的JSON文档型数据结构,可有效加快新应用程序和数字化体验的开发速度。
 展开
展开



