复制组副本间通过拷贝和重放同步日志实现数据同步。
一个复制组由一个或者多个节点组成。复制组内有两种不同的角色:主节点和备节点。正常情况下,一个复制组内有且只有一个主节点,其余为备节点。
主节点是复制组内唯一接收写操作的成员。当发生写操作时,主节点写入数据,并记录同步日志。
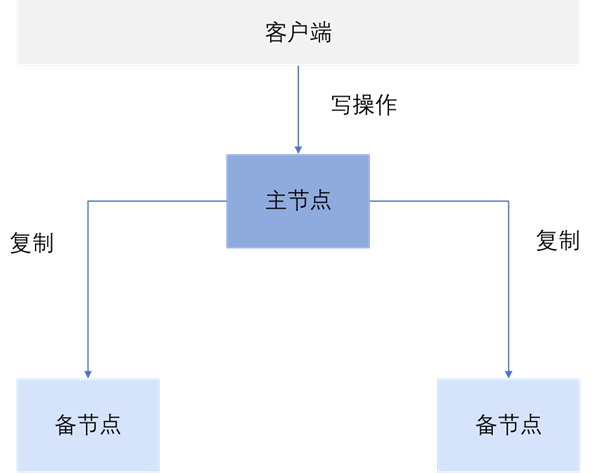
备节点持有主节点数据的副本,一个复制组可以有多个备节点。
备节点从主节点异步复制同步日志文件,并通过重放同步日志实现数据复制。SequoiaDB 默认采用“最终一致性”策略,在复制过程中,从备节点上访问的数据可能不是最新的,但副本间的数据最终保持一致。
SequoiaDB 采用同步日志方式进行副本间的数据同步。同步日志文件存放于节点数据目录下的 replicalog 目录中,默认总大小为 64*20MB。同步日志文件的大小和个数可以通过参数 logfilesz 和 logfilenum 进行设置。
以节点 11830 的数据目录为例,当节点首次启动时,节点进程会生成以下同步日志文件:
$ ls -l /opt/sequoiadb/database/data/11830/replicalog -rw-r----- 1 sdbadmin sdbadmin_group 67174400 10月 12 14:10 sequoiadbLog.0 -rw-r----- 1 sdbadmin sdbadmin_group 67174400 10月 11 17:34 sequoiadbLog.1 -rw-r----- 1 sdbadmin sdbadmin_group 67174400 10月 11 17:34 sequoiadbLog.10 -rw-r----- 1 sdbadmin sdbadmin_group 67174400 10月 11 17:34 sequoiadbLog.11 -rw-r----- 1 sdbadmin sdbadmin_group 67174400 10月 11 17:34 sequoiadbLog.12 ... -rw-r----- 1 sdbadmin sdbadmin_group 67174400 10月 11 17:34 sequoiadbLog.6 -rw-r----- 1 sdbadmin sdbadmin_group 67174400 10月 11 17:34 sequoiadbLog.7 -rw-r----- 1 sdbadmin sdbadmin_group 67174400 10月 11 17:34 sequoiadbLog.8 -rw-r----- 1 sdbadmin sdbadmin_group 67174400 10月 11 17:34 sequoiadbLog.9 -rw-r----- 1 sdbadmin sdbadmin_group 69632 10月 11 17:34 sequoiadbLog.meta
用户可通过 sdbdpsdump 工具查看写入的同步日志,示例如下:
插入一条记录
> db.sample.employee.insert({a: 1}) 查看同步日志
$ ./bin/sdbdpsdump -s ./database/data/11830/replicalog
输出结果如下:
...
Version: 0x00000001(1)
LSN : 0x00000000000000ec(236)
PreLSN : 0x000000000000009c(156)
Length : 80
Type : INSERT(1)
FullName : sample.employee
Insert : { "_id": { "$oid": "5c88afe31a3f5822754040d0" } , "a": 1 }
Note:
- LSN 是指同步日志在同步日志文件中的偏移,每条同步日志都对应唯一的 LSN 号。
- 同步日志是循环写入文件的,当所有文件被写满时,同步日志将从第一个文件开始覆盖写入,又称为同步日志翻转。
复制组中节点之间的同步机制包括增量同步和全量同步。
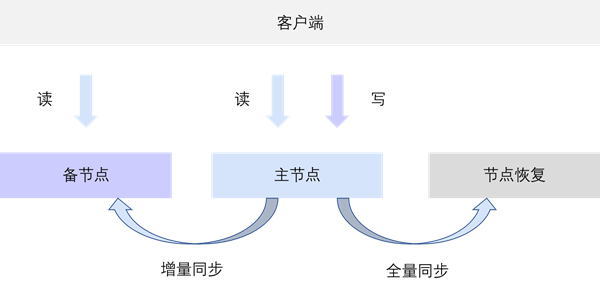
数据同步在以下两种节点间进行:
在数据节点和编目节点中,任何增删改操作均会写入同步日志。节点会先将同步日志写入缓冲区,再异步写入同步日志文件中。
增量同步前节点间存在两种状态:
增量同步时,备节点会选择源节点发送复制请求。源节点收到复制请求后,会打包备节点请求的同步点之后的同步日志,并发送给备节点。备节点接收到同步数据包后,通过重放同步日志实现数据同步。
当所有节点的数据版本差距在一个很小的窗口,源节点为主节点;当备节点的数据版本与主节点相差过大时,源节点为其他数据版本相近的备节点;当节点间发生版本冲突时,以当前主节点的数据版本为准,如果冲突不能解决时,目标备节点进入全量同步;当备节点请求的同步日志既不存在于源节点的同步日志缓存区,也不存在于同步日志文件中时,目标备节点进入全量同步;当复制组内不存在主节点时,任何同步操作均无法进行。
在复制组内,特定情况需要进行全量同步才能保障节点之间数据的一致性,具体情况下:
Note:
正常重启后,如果数据版本仍在可同步范围内则不会触发全量同步。
全量同步时,备节点会尝试从本地进行全量或阶段性的数据及同步日志恢复。当本地数据不完整时,备节点会向源节点请求数据,源节点将数据打包后作为大数据块发送给备节点。同步期间,备节点对外不提供服务,同时源节点发生的数据改变会被复制到本地;同步完成后,备节点的原有数据会被废弃。
全量同步会极大地影响整个组的性能,甚至导致其他备节点同步性能降低。建议通过如下方式避免全量同步:
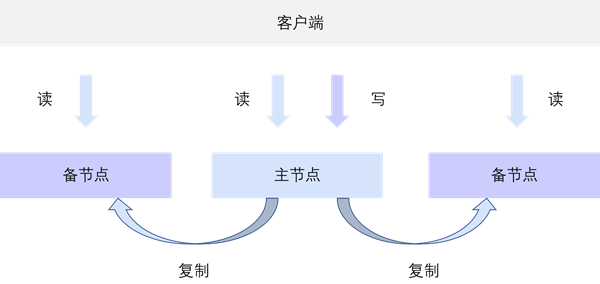
协调节点通过将读请求发送至不同的数据副本,以降低读写 I/O 冲突,提升集群整体的吞吐量。
所有的写请求都只会发往主节点。
读请求会按照会话的属性选择组内节点。
例如,集合 sample.employee 落在数据组 group1 上,group1 上有三个节点 sdbserver1:11830、sdbserver2:11830 和 sdbserver3:11830,其中 sdbserver1:11830 是主节点:
> var db = new Sdb ( 'sdbserver1', 11810 )
> // 插入数据后,查询走主节点
> db.sample.employee.insert( { a: 1} )
> db.sample.employee.find().explain( {Run: true } )
{
"NodeName": "sdbserver1:11830"
"GroupName": "group1"
"Role": "data"
...
}
>
> // 设置会话上读请求的策略:优先从备节点上读,查询走备节点
> db.setSessionAttr( { PreferredInstance: 's' } )
> db.sample.employee.find().explain( {Run: true } )
{
"NodeName": "sdbserver2:11830"
"GroupName": "group1"
"Role": "data"
...
}
>
> // 再次插入数据后,查询走主节点
> db.sample.employee.insert( { a: 1} )
> db.sample.employee.find().explain( {Run: true } )
{
"NodeName": "sdbserver1:11830"
"GroupName": "group1"
"Role": "data"
...
}
在分布式系统中,一致性是指数据在多个副本之间数据保持一致的特性。
为了提升数据的可靠性和实现数据的读写分离,SequoiaDB 巨杉数据库默认采用“最终一致性”策略。在读写分离时,读取的数据在某一段时间内可能不是最新的,但副本间的数据最终是一致的。
写请求处理成功后,后续读到的数据一定是当前组内最新的,但是这样会降低复制组的写入性能。
用户可以通过 createCL() 在创建集合时指定 ReplSize 属性,来提高数据的一致性和可靠性。
> var db = new Sdb ( 'sdbserver1', 11810 )
> // 写操作需要等待所有的副本都完成才返回,强一致性
> db.sample.createCL( 'employee1', { ReplSize: 0 })
> // 写操作等待一个副本完成就会返回,最终一致性
> db.sample.createCL( 'employee2', { ReplSize: 1 })





