本文档将介绍如何通过减少服务器实现集群缩容。
原集群总共有六台机器,每台机器均部署了协调节点与数据节点。其中 sdbserver1、sdbserver2 和 sdbserver3 这三台机器共同组成了编目节点组 SYSCatalogGroup 与数据节点组 group1。sdbserver4、sdbserver5 和 sdbserver6 这三台机器组成了另外一个数据节点组 group2。
集群机器缩容架构图
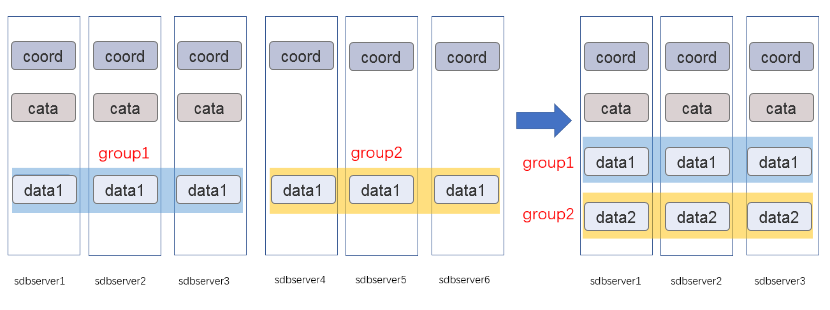
如果要对六台服务器中的三台进行回收,数据库就需要实施规模缩减操作。 规模缩减后,sdbserver1、sdbserver2 和 sdbserver3 三台机器上已经部署的编目节点组和数据节点组 group1 保持不变,同时将 sdbserver4、sdbserver5 和 sdbserver6 三台机器部署的数据节点组 group2 迁移到 sdbserver1、sdbserver2 和 sdbserver3 这三台机器上,端口使用 11830,达到保持原数据库架构不变,缩减机器规模的目的。
连接 sdbserver4 的协调节点
> db = new Sdb("sdbserver4",11810) 获取复制组 group2 的对象
> var rg2 = db.getRG("group2") 在给复制组 group2 扩展时,首先判断 sdbserver1、sdbserver2 和 sdbserver3 机器的 11830 端口是否被占用,sdbcm 进程是否对 /opt/sequoiadb/data 路径有写操作权限
$ netstat -nap | grep 11830 $ ls -l /opt/sequoiadb/ | grep data
在 sdbserver1 中扩展复制组 group2 的数据节点
> var node = rg2.createNode("sdbserver1",11830,"/opt/sequoiadb/data/11830") 启动 sdbserver1 中新增的数据节点
> node.start()
在 sdbserver2 中扩展复制组 group2 的数据节点
> node = rg2.createNode("sdbserver2",11830,"/opt/sequoiadb/data/11830") 启动 sdbserver2 新增的数据节点
> node.start()
在 sdbserver3 这台机器扩展复制组 group2 的数据节点
> node = rg2.createNode("sdbserver3",11830,"/opt/sequoiadb/data/11830") 启动 sdbserver3 新增的数据节点
> node.start()
检查复制组 group2 是否正确新增了 sdbserver1:11830、sdbserver2:11830 和 sdbserver3:11830 三个数据节点,检查 group2 的主数据节点部署在哪台机器上,查看 GroupName="group2" 的 PrimaryNode 字段
> db.listReplicaGroups()
连接复制组 group2 的主数据节点,假设 group2 组旧的主数据节点是 sdbserver4 机器的 11820 进程
> datadbm = new Sdb("sdbserver4",11820) 查看并记录复制组 group2 的主数据节点的 LSN 号
> masterlsn.offset = datadbm.snapshot(SDB_SNAP_SYSTEM).next().toObj()["CurrentLSN"]["Offset"] > masterlsn.version = datadbm.snapshot(SDB_SNAP_SYSTEM).next().toObj()["CurrentLSN"]["Version"]
分别连接复制组 group2 新增的数据节点,查看新增的数据节点 LSN 号,查看 sdbserver1:11830 节点的 LSN 号
> datadb1 = new Sdb("sdbserver1",11830)
> datadb1.snapshot(SDB_SNAP_SYSTEM).next().toObj()["CurrentLSN"]["Offset"]
> datadb1.snapshot(SDB_SNAP_SYSTEM).next().toObj()["CurrentLSN"]["Version"] 查看 sdbserver2:11830 节点的 LSN 号
> datadb2 = new Sdb("sdbserver2",11830)
> datadb2.snapshot(SDB_SNAP_SYSTEM).next().toObj()["CurrentLSN"]["Offset"]
> datadb2.snapshot(SDB_SNAP_SYSTEM).next().toObj()["CurrentLSN"]["Version"] 查看 sdbserver3:11830 节点的 LSN 号
> datadb3 = new Sdb("sdbserver3",11830)
> datadb3.snapshot(SDB_SNAP_SYSTEM).next().toObj()["CurrentLSN"]["Offset"]
> datadb3.snapshot(SDB_SNAP_SYSTEM).next().toObj()["CurrentLSN"]["Version"]
等待复制组 group2 新增的数据节点 LSN 号停止增长并且与复制组 group2 主数据节点的 LSN 号相同。在新增数据节点的 LSN 号与主数据节点的 LSN 号保持一致后,使用协调节点的连接连续多次查看整个数据库的数据读写情况,如果数据读、写操作指标静止不变,则判断新增数据节点已经完成日志同步。
查看数据库快照
> db.snapshot(SDB_SNAP_DATABASE)
移除复制组 group2 的旧主数据节点,假设复制组 group2 旧的主数据节点是 sdbserver4 机器的11820进程
> var rg = db.getRG("group2")
> rg.removeNode("sdbserver4",11820) 检查复制组 group2 的选主情况,确定复制组 group2 选主成功,查看 GroupName="group2" 的 PrimaryNode 字段
> db.listReplicaGroups()
根据 PrimaryNode 的 nodeid,用户可以确定 PrimaryNode 的 HostName ,假设为 sdbserver2 机器的 11830 进程,可以直连到 sdbserver2 机器的 11830 进程,检查它是否真实选为 group2 组的主数据节点,并查看 IsPrimary 字段是否为 True
> var datadbm = new Sdb("sdbserver2",11830)
> datadbm.snapshot( SDB_SNAP_SYSTEM ) 确定复制组 group2 新选主后,移除另外两个数据节点
> rg.removeNode("sdbserver5",11820)
> rg.removeNode("sdbserver6",11820) 最后将 sdbserver4, sdbserver5, sdbserver6 这三台机器的协调节点从协调节点组中移除
> var oma = new Oma( "sdbserver4", 11790 ) > oma.removeCoord( 11810 ) > var oma = new Oma( "sdbserver5", 11790 ) > oma.removeCoord( 11810 ) > var oma = new Oma( "sdbserver6", 11790 ) > oma.removeCoord( 11810 )





