SequoiaDB 巨杉数据库支持创建全文索引,用于在大量文本中进行快速检索。与其他索引相比,全文索引通过建立词库,统计每个词条出现的频率和位置,可以快速定位关键词出现的位置,以提升检索效率。
一个新的文档从插入集合到可被搜索会有一定的延迟,延迟长短取决于构建全文索引的速度。索引的构建主要分为以下两种情况:
SequoiaDB 巨杉数据库使用 Elasticsearch 作为全文检索引擎实现全文索引。全文索引与普通索引的最大区别在于,索引数据不是存在于数据节点的索引文件中, 而是存储在 Elasticsearch 中。全文索引的实现涉及以下三个角色:
在集合上使用全文索引进行检索时,协调节点先将请求分发至集合相关的所有数据组,由数据节点转发搜索请求至 Elasticsearch 集群。Elasticsearch 搜索到相关索引信息后,数据节点根据索引信息查找数据,并将真实数据返回至协调节点,协调节点将数据汇总后返回至客户端。其流程图如下:
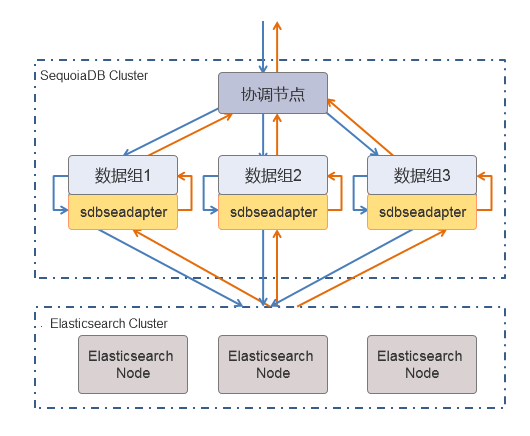
sdbseadapter 是数据节点与 Elasticsearch 交互的桥梁。SequoiaDB 通过该工具实现全文索引功能,具体参数如下:
| 参数名 | 缩写 | 描述 |
|---|---|---|
| --help | -h | 获取帮助选项 |
| --version | 获取版本信息 | |
| --confpath | -c | 配置文件路径(不需指定文件名) |
| --diaglevel | -v | 日志级别,默认值为 3 |
| --datanodehost | 数据节点所在主机名 | |
| --datasvcname | 数据节点服务端口号 | |
| --searchenginehost | 搜索服务器(Elasticsearch)所在主机名 | |
| --searchengineport | 搜索服务器(Elasticsearch)服务端口号,默认值为 9200 | |
| --idxprefix | -p | 全文检索适配器在搜索服务器(Elasticsearch)上创建索引时使用的索引名前缀,默认值为空 前缀名最大长度为 16 个字符,可包含英文字母(大小写不敏感)、阿拉伯数字及下划线,但不能以下划线开头 同一个复制组对应的适配器必须使用相同的前缀,不同的 SequoiaDB 集群在共用相同的搜索服务器时,必须配置不同的前缀名;建议一个 SequoiaDB 集群包含的所有适配器使用相同的前缀 |
| --bulkbuffsize | 批量操作缓存大小,默认值为 10,单位为 MB,取值范围为[1, 32] | |
| --optimeout | -t | 在搜索服务器(Elasticsearch)上操作的超时时间,默认值为 10000,单位为 ms,取值范围为[3000, 3600000] |
| --stringmaptype | -s | 字符串类型(包括字符串数组)的字段在搜索服务器(Elasticsearch)上映射的类型,默认值为 1,具体取值如下: 1:表示"text"类型,字符串在搜索引擎上会被分析和拆词,适合于全文检索场景 2:表示"keyword",字符串不会被拆词,适合于字符串的精确查询、聚合运算等 3:表示同时映射成"text"和"keyword"类型,直接使用字段名时使用的是其"text"类型,而要使用其"keyword"类型,则需要使用 field_name.keyword 的格式,详细内容可参考 Elasticsearch 文档中的字段类型介绍 |
| --connlimit | -l | 全文检索适配器与搜索服务器之间的连接数上限,默认值为 50,取值范围为[1, 65535] |
| --conntimeout | -o | 全文检索适配器与搜索服务器之间连接空闲时的超时时间,超时后连接将被释放,默认值为 1800,单位为秒,取值范围为[60, 86400] |
| --scrollsize | 全文检索适配器使用 scroll 方式(查询条件中不设置 from/size 参数)从搜索服务器(Elasticsearch)获取查询结果时,每批结果的记录数,默认值为 1000,取值范围为[50, 10000] |
用户在使用全文索引之前,需要先完成 Elasticsearch 集群、SequoiaDB 集群及搜索引擎适配器的部署。
Note:
由于不同集群间集合的 UniqueID、原始索引名等可能相同,会导致 Elasticsearch 中生成的索引名重复。因此建议每个 SequoiaDB 集群使用不同的 Elasticsearch 集群,避免集群混用造成的数据错误。
下述示例以 Elasticsearch 安装目录为 /opt/elasticsearch-6.8.5、对外服务的 http 端口为 9200 ,介绍部署步骤。
在 Elasticsearch 官网下载 Elasticsearch 安装包
Note:
当前 SequoiaDB 适配的 Elasticsearch 版本为 6.8.5
解压安装包
$ tar -xzf elasticsearch-6.8.5.tar.gz
切换至 Elasticsearch 安装目录
$ cd /opt/elasticsearch-6.8.5
修改 Elasticsearch 集群配置
Note:
- 用户可根据实际需求参考 Elasticsearch 官方文档修改 Elasticsearch 集群配置。
- 在测试环境中,支持全默认配置启动,即默认启动单节点的 Elasticsearch 集群。在实际使用中,用户应配置多节点的 Elasticsearch 集群。
启动 Elasticsearch
$ ./bin/elasticsearch -d
查看是否启动成功
$ jps
输出如下内容表示启动成功:
10183 Elasticsearch
查看 Elasticsearch 集群状态
$ curl -XGET "sdbserver:9200/"
SequoiaDB 集群包含的每一个数据节点均需要启动一个对应的适配器节点,二者需要运行在同一台主机上。下述示例以 SequoiaDB 安装目录为 /opt/sequoiadb、已存在的数据节点为 11820、11830、11840,介绍部署步骤。
切换至 conf 目录
$ cd /opt/sequoiadb/conf
在当前目录下创建 seadapter 目录
$ mkdir seadapter
切换至 seadapter 目录
$ cd seadapter
创建各数据节点对应的适配器目录
$ mkdir 11820 11830 11840
将适配器的配置文件分别拷贝至各节点对应的目录中
$ cp ../samples/sdbseadapter.conf 11820 $ cp ../samples/sdbseadapter.conf 11830 $ cp ../samples/sdbseadapter.conf 11840
分别修改上述配置文件,以节点 11830 为例,配置内容如下:
datanodehost=sdbserver datasvcname=11830 searchenginehost=sdbserver searchengineport=9200 diaglevel=3 optimeout=30000 bulkbuffsize=10
启动各节点对应的适配器
$ nohup sdbseadapter -c /opt/sequoiadb/conf/seadapter/11820 & $ nohup sdbseadapter -c /opt/sequoiadb/conf/seadapter/11830 & $ nohup sdbseadapter -c /opt/sequoiadb/conf/seadapter/11840 &
查看所有适配器进程是否均已启动成功
$ ps -ef | grep sdbseadapter
输出如下信息则启动成功:
sdbseadapter(11827) A sdbseadapter(11837) A sdbseadapter(11847) A
SequoiaDB 通过在查询中指定 Elasticsearch 的搜索条件,以进行全文检索。语法如下:
find( { "": { "$Text": <search command> } } )
其中 <search command> 是 Elasticsearch 的搜索条件,需要使用 Elasticsearch 的 DSL(Domain Specific Language)语法。详情可参考 Elasticsearch DSL 官方文档。
示例
创建集合 sample.employee
> var cl = db.createCS('sample').createCL('employee')创建全文索引
> cl.createIndex('idx_1', {"first_name": "text", "last_name": "text", "age": "text", "about": "text", "interests": "text"})将数据插入 sample.employee 中
> cl.insert({"first_name": "John", "last_name": "Smith", "age": 25, "about": "I love to go rock climbing", "interests": ["sports", "music"]})
> cl.insert({"first_name": "Jane", "last_name": "Smith", "age": 32, "about": "I like to collect rock albums", "interests": ["music"]})
> cl.insert({"first_name": "Douglas", "last_name": "Fir", "age": 35, "about": "I like to build cabinets", "interests": ["forestry"]})使用全文索引对集合 sample.employee 中 about 字段包含的"rock climbing"进行模糊查询
> cl.find({"": {"$Text": {"query": {"match": {"about": "rock climbing"}}}}}).hint({"": "idx_1"})
{
"_id": {
"$oid": "5a8f8d9c89000a0906000000"
},
"first_name": "John",
"last_name": "Smith",
"age": 25,
"about": "I love to go rock climbing",
"interests": [
"sports",
"music"
]
}
{
"_id": {
"$oid": "5a8f8d9f89000a0906000001"
},
"first_name": "Jane",
"last_name": "Smith",
"age": 32,
"about": "I like to collect rock albums",
"interests": [
"music"
]
}
Return 2 row(s).更多操作可参考
| 操作 | 说明 |
|---|---|
| query.explain() | 获取查询的访问计划 |
| SdbCollection.dropIndex() | 删除指定的全文索引 |




