用户的数据呈现出多样性,这些数据可以归纳为以下三类:
SequoiaDB 巨杉数据库支持 JSON 存储与块存储,能够很轻松地满足用户对多样性数据的存储与管理的要求。
SequoiaDB 巨杉数据库的数据管理模型如图 1 所示, 该模型展示了 SequoiaDB 的数据存储模型以及集群组成所涉及的基本概念。
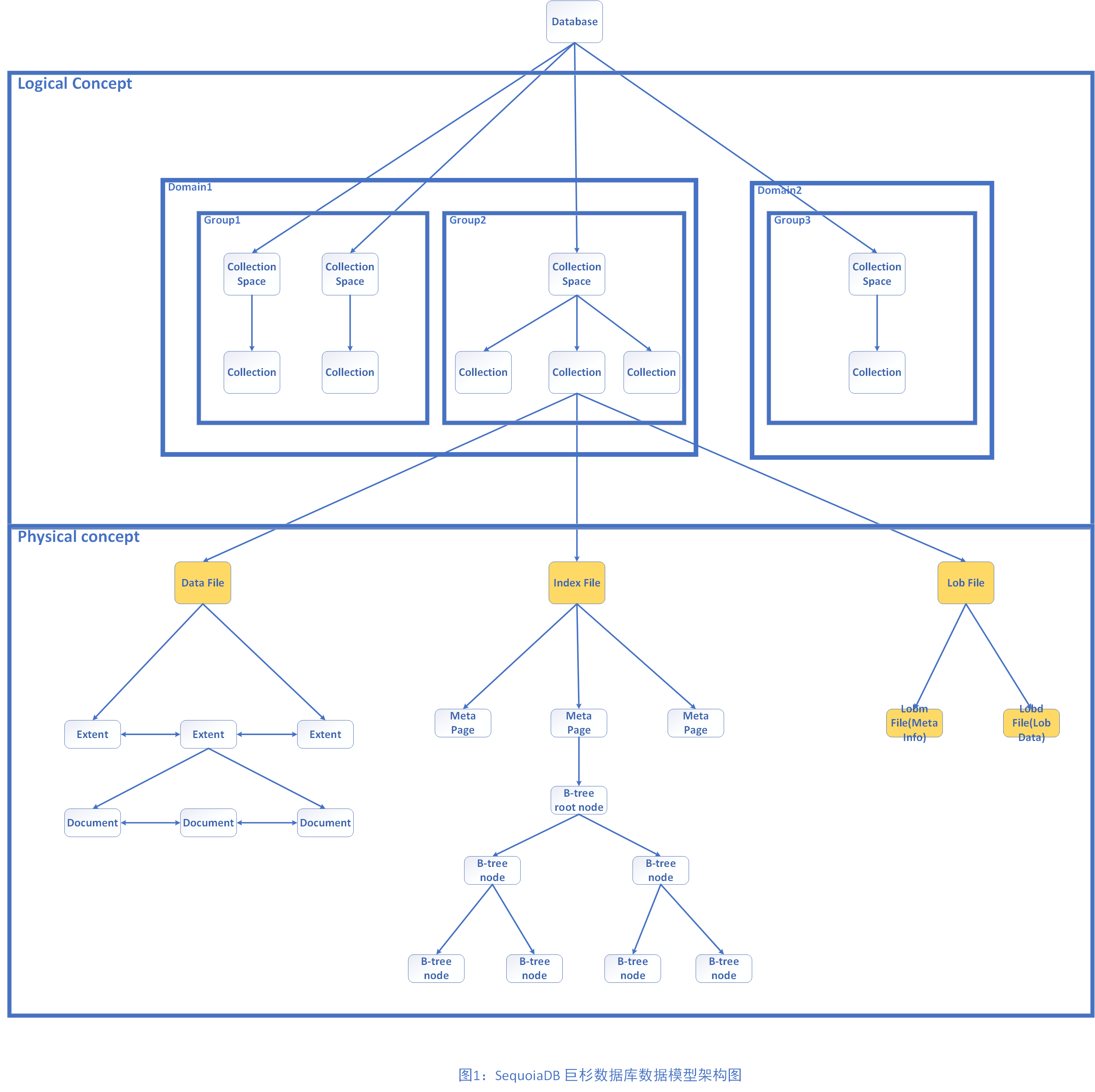
图 1 的数据模型中,数据文件最终都需要在磁盘文件中进行持久化存储,与之相关的三个概念如下:
在图 1 的数据模型中,与结构/半结构化数据存储相关的三个核心逻辑概念包括:
一个集合空间可以包含多个集合,一个集合会包含若干个数据块。集合使用链表把这些数据块串联起来。当向集合中插入文档时,需要从数据块中分配空间。如果当前数据块没有足够空间,后台线程将分配新的数据块(必要时对数据文件进行扩展),并把新的数据块挂到该集合的数据块链表上。每个数据块内的记录也通过链表的形式组织起来,这样在进行表扫描时,可顺序读取数据块内的所有记录。
在结构/半结构化数据存储的基础上,与非结构化数据存储相关的核心逻辑概念包括:
大对象依附于普通集合存在。当用户上传一个大对象时,系统为其分配一个唯一的 OID 值, 后续对该大对象的操作可通过该值来进行指定。
在图 1 数据模型架构中,与集群组成相关的四个核心逻辑概念包括:
SequoiaDB 的集群管理相关概念的关系如图 2 所示。

在集群中,一个复制组可以包含 1~7 个节点。一个域可以包含一个或者若干个复制组,以提供给专门的业务使用。当把集合空间创建在一个域上的时候,该集合空间下的所有集合将根据该集合的分区键自动切分到域所包含的复制组中。集合的数据切分对提升性能起到极大的促进作用。关于集群和数据切分的详细介绍,可分别参考复制组及分区章节的内容。
在 SequoiaDB 中,索引是一种特殊的数据对象。索引本身不作为保存用户数据的容器,而是作为一种特殊的元数据,用以提高数据访问的效率。
SequoiaDB 提供自增字段能力。在创建集合时,用户可以指定一个或者多个字段为自增字段。





