用户可以使用表分区或数据库分区提高数据访问性能,但在数据量快速增长的场景下性能会逐渐下降,多维分区可以解决这一问题。本文档将介绍多维分区的实现原理和操作实例。
多维分区主要用于处理既要减少数据访问量,又要提高数据并行计算能力的场景。多维分区示意图:
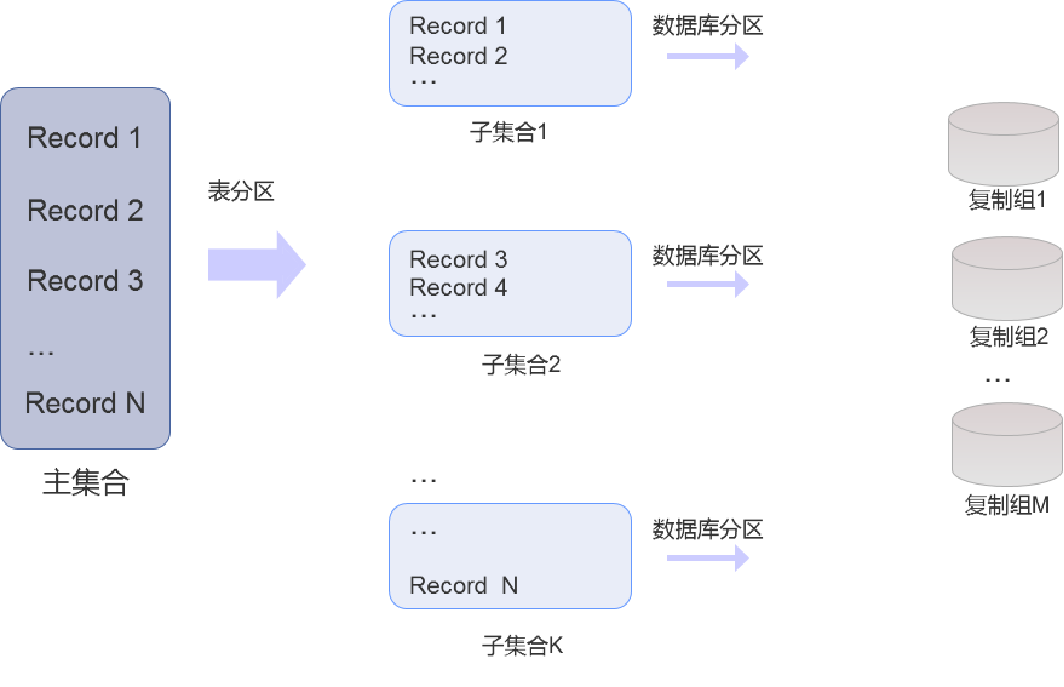
下面以银行业务账单为例,简单介绍一下多维分区的作用。
多维分区在操作上,可以先对子集合做数据库分区,然后再通过表分区将子集合挂载到主集合上。
创建主集合 main.bill ,分区键为 bill_date ,分区方式为范围分区(range)
> db.createCS("main")
> db.main.createCL("bill", {IsMainCL: true, ShardingKey: {bill_date: 1}, ShardingType: "range"})创建子集合 bill.date_201905 ,分区键为帐号 id 字段,分区方式为散列分区(hash),hash 值总数为 4096 个, 集合所在复制组为 group1
> db.createCS("bill")
> db.bill.createCL("date_201905", {ShardingKey: {id: 1}, ShardingType: "hash", Partition: 4096, Group: "group1"})执行切分命令,将集合 bill.date_201905 中,帐号 id 字段 hash 值范围在[2048, 4096)的记录,从复制组 group1 切分到复制组 group2
> db.bill.date_201905.split("group1", "group2", {Partition: 2048}, {Partition: 4096})通过挂载操作,将主集合 main.bill 和子集合 bill.date_201905 进行关联
> db.main.bill.attachCL("bill.date_201905", {LowBound: {bill_date: "201905"}, UpBound: {bill_date: "201906"}})




