SequoiaDB 巨杉数据库使用的是多线程模型,不同类型的线程用于处理不同的任务。对于集群中的一个节点,它要处理的任务主要包括:
SequoiaDB 设计了一系列的代理线程及系统线程来处理多种类型的任务,基本的线程模型如下图:
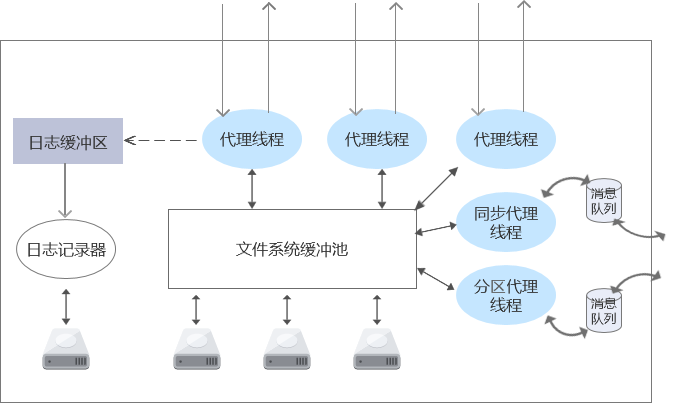
图中,代理线程用于处理来自用户的请求;同步代理线程用于副本节点之间的数据同步;分区代理线程则是处理协调节点发给数据节点的请求。除此之后,还有一系列的独立线程,用于连接请求监听、网络数据收发等。下面对几种典型场景进行介绍。
不同类型的节点对外提供的服务不同,SequoiaDB 中的节点使用不同的端口号来提供不同类型的服务。客户端通过服务端口连接到协调节点时,协调节点上会生成一个新的代理线程,直连其它类型节点的情况与之类似。与之紧密关联的另一个重要概念是会话,在创建代理线程时,会同时创建一个会话,它是一个内存数据结构,用于保存当前连接上交互的上下文。
当协调节点需要与数据节点交互时,需要通过 shard 平面(服务于集群内部通讯的端口)连接到数据节点,在数据节点上会对应地创建一个分区代理线程及会话。如果协调节点同时与多个复制组的数据节点交互,则在对应的每个数据节点上都会生成一个分区线程及会话。
SequoiaDB 集群在处理用户请求时,通常会涉及到多种类型节点上的多个会话,会话需要与具体的线程绑定之后才能进行任务处理。典型的会话模型如下图:
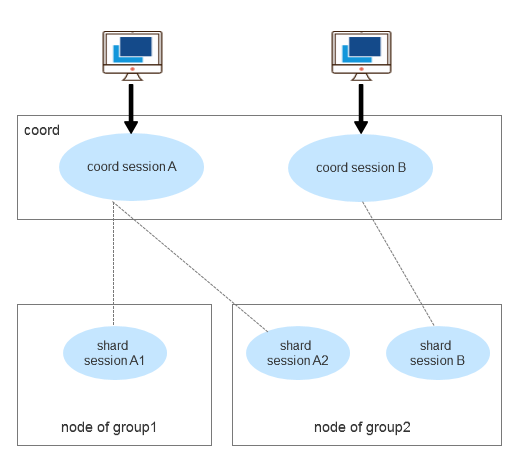
当协调节点或数据节点需要从编目节点获取元数据时,会向编目节点发送数据请求。编目节点上是使用单线程的模型来处理这些请求的。
在 SequoiaDB 中,会话使用了两种典型的模型:同步会话模型和异步会话模型。下面分别对它们进行简要介绍。由于会话与线程是一对一绑定的,因此会话同时也是指会话线程。
同步会话的基本原理如下图。
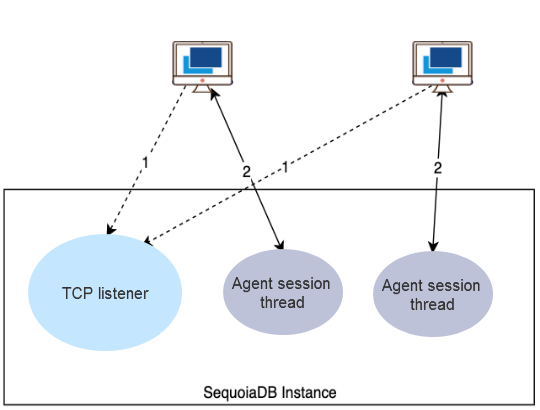
同步会话通常与对外提供的特定服务相关,服务线程在指定的端口上开启监听。当客户端通过该端口连接服务端时,监听线程会创建一个独立的代理线程。代理线程开始运行后,会创建一个对应的会话结构,并与之绑定。之后客户端就直接与这个代理线程进行通信,而监听线程则继续监听新的连接请求。在连接断开前,会话线程会一直等待客户端发送的请求,当请求到达时,执行对应的处理逻辑,生成执行结果,将结果返回给客户端,然后继续等待下一个请求。当连接断开时,该会话线程会被会话管理器回收或销毁。
在巨杉数据库中,使用客户端工具(如 sdb)直连各节点的本地服务端口(svcname)时产生的会话,就是同步会话。
SequoiaDB 巨杉数据库的异步会话机制是基于 boost ASIO 库实现的,其基本原理如下图。
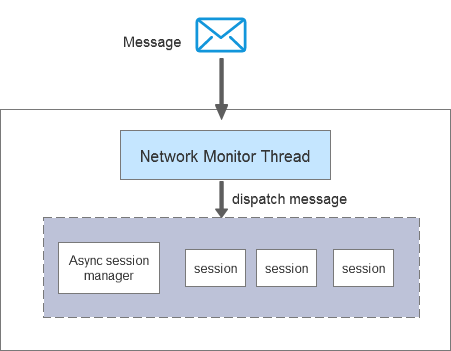
在 SequoiaDB 集群中,节点间的交互广泛使用异步会话机制,以最大限度地提高并发处理能力,减少对 socket 等系统资源的占用。如数据节点处理协调节点发送的消息的分片会话和增量同步会话等。
数据库系统内部通常包含复杂的处理控制逻辑,因此也就存在着多种类型的控制线程。此处仅对其中最核心的两种线程进行介绍。
在进行数据写操作时,数据变更最初发生在内存中。为了实现数据的持久化存储,需要保证数据最终写入到磁盘文件中。巨杉数据库使用了 MMAP 机制将数据文件映射到内存中,系统会自动进行内存中数据的刷盘。脏页清除任务则是在此被动刷盘的基础上,提供了可由用户控制的主动刷盘方式。用户可通过配置,实现特定时间间隔或变更数据量的情况下触发后台的刷盘动作,刷盘工作线程数据也可根据需要灵活配置。
巨杉数据库使用复制日志来支持副本间数据的同步以及事务能力。在集群模式下,节点上的所有写操作都需要记录复制日志,且日志需要持久化存储到磁盘上的文件中。节点使用一组相同大小的复制日志文件来进行日志存储,该节点上所有的日志顺序地写入这组文件中。为了提高并发操作时的性能,系统提供了复制日志缓冲区,执行操作的线程在写日志时,先写入到日志缓冲区中,然后由日志持久化线程负责将日志刷到磁盘上。日志缓冲区的大小可使用参数 logbuffsize 进行配置。





