本文档主要介绍在两地三中心的部署方案下,如何应对不同级别的灾难。
当复制组中超过半数节点发生故障,该复制组将无法提供读写服务。针对该情况,用户需参考节点故障场景进行灾难恢复。如果故障节点未超过半数,用户仅需修复故障节点并恢复节点数据即可。
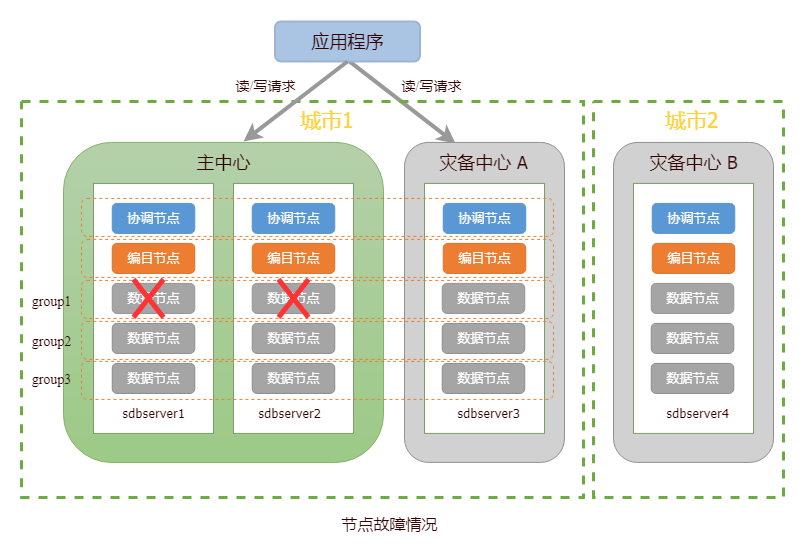
当主中心发生故障,主中心所在集群将失去半数以上的节点,导致无法对外提供读写服务。针对该情况,用户需参考数据中心故障场景进行灾难恢复。
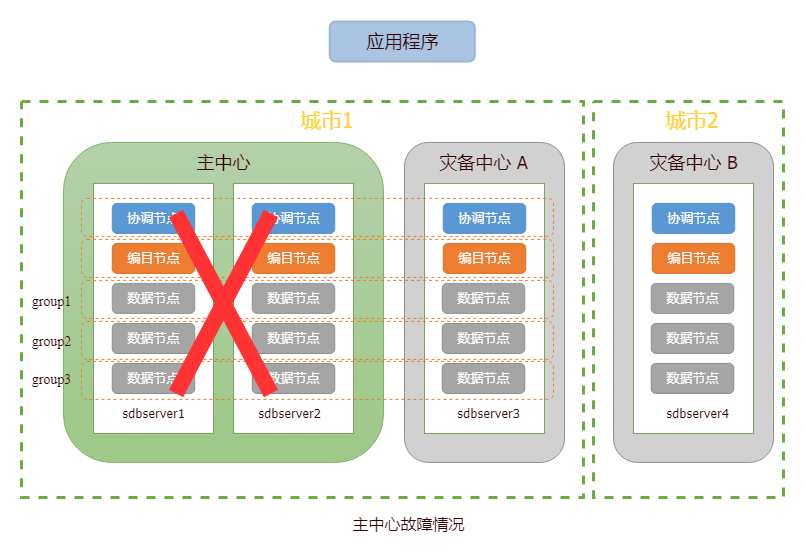
当灾备中心A发生故障,主中心仍可提供读写服务。针对该情况,用户仅需修复故障中心并恢复节点数据即可。
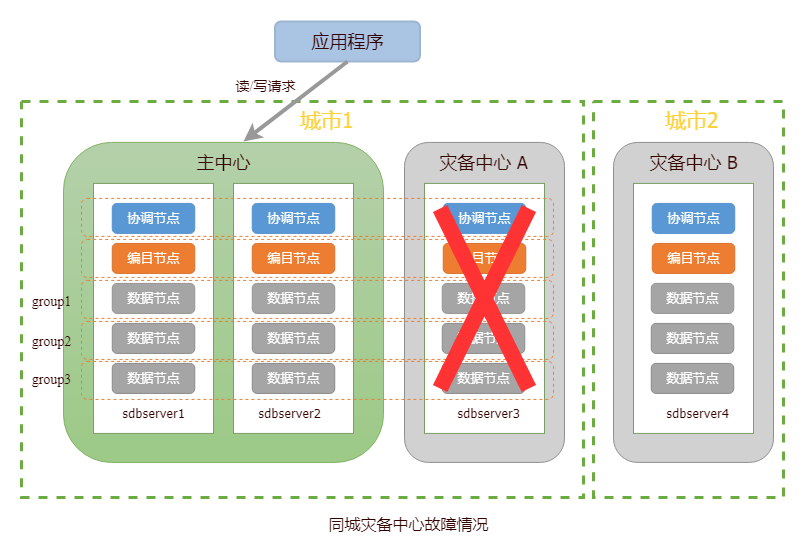
当灾备中心B发生故障,集群仍对外提供读写服务。针对该情况,用户仅需修复故障中心,并恢复日志重放进程即可。

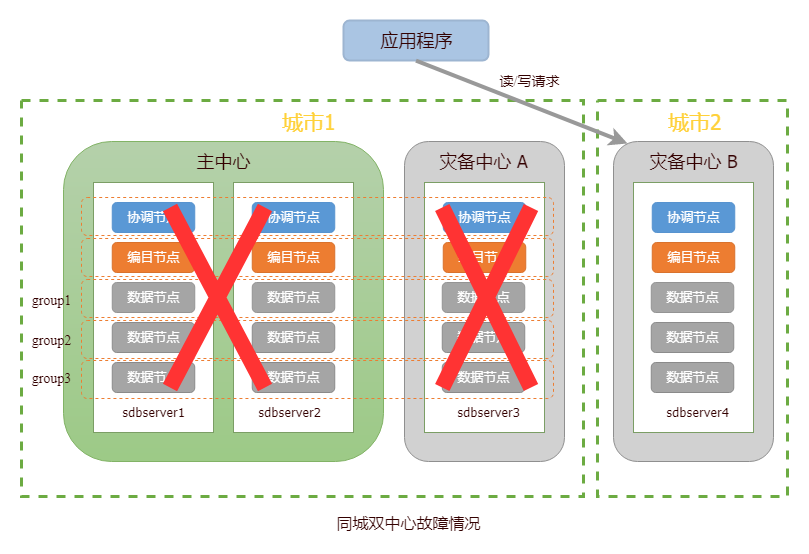
当主中心和灾备中心A发生故障,本地集群将无法提供读写服务。针对该情况,用户需将应用请求发送至灾备中心B所在集群,并修复故障中心。待故障修复后再将应用请求切换回主中心所在集群。
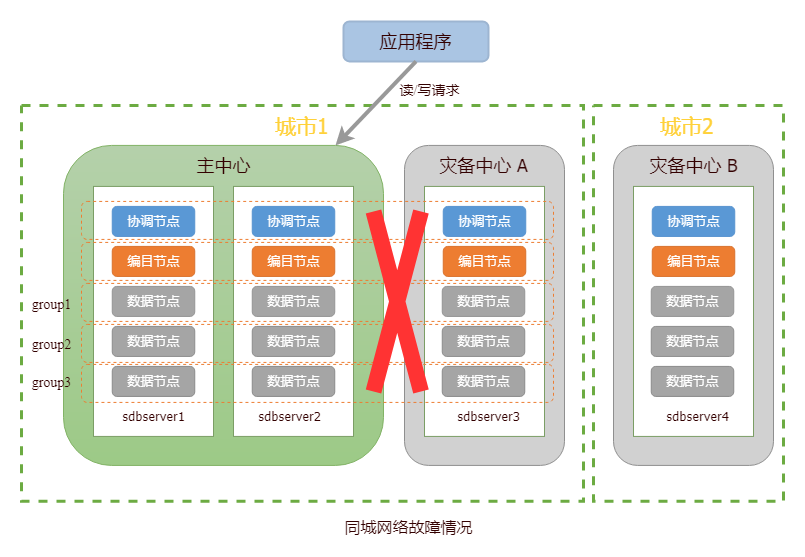
当数据中心发生网络故障,集群仍可提供读写服务。针对该情况,用户仅需修复网络故障并恢复节点数据即可。
SequoiaDB 巨杉数据库提供容灾切换合并工具,用于对节点故障场景和数据中心故障场景进行灾难恢复。下述以 SequoiaDB 安装目录 /opt/sequoiadb/、集群鉴权用户名“sdbadmin”和用户密码“sdbadmin”为例,介绍不同场景的灾难恢复步骤。
下述以复制组 group1 不可用为例,介绍节点故障场景的具体恢复步骤。
选择一台未发生故障的主机 sdbserver,切换至容灾工具目录
$ cd /opt/sequoiadb/tools/dr_ha
修改配置文件 cluster_opr.js
$ vim cluster_opr.js
修改内容如下:
if ( typeof(SEQPATH) != "string" || SEQPATH.length == 0 ) { SEQPATH = "/opt/sequoiadb/" ; }
if ( typeof(SDBUSERNAME) != "string" ) { SDBUSERNAME = "sdbadmin" ; }
if ( typeof(SDBPASSWD) != "string" ) { SDBPASSWD = "sdbadmin" ; }
if ( typeof(SUB1HOSTS) == "undefined" ) { SUB1HOSTS = [ "sdbserver" ] ; }
if ( typeof(COORDADDR) == "undefined" ) { COORDADDR = [ "sdbserver:11810" ] }
if ( typeof(CURSUB) == "undefined" ) { CURSUB = 1 ; }
if ( typeof(MINREPLICANUM) == "undefined" ) { MINREPLICANUM = 1 ; }
if ( typeof(NEEDREELECT) == "undefined" ) { NEEDREELECT = false }
if ( typeof(NEEDBROADCASTINITINFO) == "undefined" ) { NEEDBROADCASTINITINFO = true }
Note:
配置文件的参数说明可参考容灾切换合并工具。
剔除故障节点,剔除后复制组将恢复读写服务
$ sh detachGroupNode.sh
修复故障节点
将修复后的节点重新加入复制组
$ sh attachGroupNode.sh
通过 SDB Shell 检查节点间数据是否一致
> db.snapshot(SDB_SNAP_HEALTH, {GroupName: "group1"}, {IsPrimary: null, CompleteLSN: null})
对比主备节点间字段 CompleteLSN 的值,如果保持一致则说明节点数据一致
{
"IsPrimary": true,
"CompleteLSN": 228
}
{
"IsPrimary": false,
"CompleteLSN": 228
}
{
"IsPrimary": false,
"CompleteLSN": 228
}
Note:
如果主备节点间字段 CompleteLSN 的值不一致,用户需等待片刻,待节点数据同步后再次检查节点数据是否一致。
在当前复制组中重新选主
> var rg = db.getRG("group1")
> rg.reelect({Seconds: 60})当数据中心故障导致集群不可用,需要通过以下步骤进行恢复:
下述以主中心整体故障为例,介绍数据中心故障场景的具体恢复步骤。
划分子网
将正常机房划分为 SUB1,故障机房划分为 SUB2
| 子网 | 主机 |
|---|---|
| SUB1 | sdbserver3 |
| SUB2 | sdbserver1、sdbserver2 |
集群分裂
集群分裂操作用于将灾备中心A从集群中分裂,使其成为具备读写功能的独立集群。分裂完成后,将由灾备中心A对外提供服务。
开启自动全量同步,避免节点重启失败
逐一修改所有故障节点的配置文件 sdb.conf
$ vim /opt/sequoiadb/conf/local/<端口号>/sdb.conf
修改内容如下:
... dataerrorop=1 ...
选择 SUB1 的主机,切换至容灾工具目录
$ cd /opt/sequoiadb/tools/dr_ha
修改配置文件 cluster_opr.js
$ vim cluster_opr.js
修改内容如下:
if ( typeof(SUB1HOSTS) == "undefined" ) { SUB1HOSTS = [ "sdbserver3" ] ; }
if ( typeof(SUB2HOSTS) == "undefined" ) { SUB2HOSTS = [ "sdbserver1", "sdbserver2" ] ; }
if ( typeof(COORDADDR) == "undefined" ) { COORDADDR = [ "sdbserver3:11810" ] }
if ( typeof(CURSUB) == "undefined" ) { CURSUB = 1 ; }
if ( typeof(ACTIVE) == "undefined" ) { ACTIVE = true ; }执行分裂操作
$ sh split.sh
修复故障中心
选择 SUB2 的任意一台主机,切换至容灾工具目录
$ cd /opt/sequoiadb/tools/dr_ha
修改配置文件 cluster_opr.js
$ vim cluster_opr.js
修改内容如下:
if ( typeof(SUB1HOSTS) == "undefined" ) { SUB1HOSTS = [ "sdbserver3" ] ; }
if ( typeof(SUB2HOSTS) == "undefined" ) { SUB2HOSTS = [ "sdbserver1", "sdbserver2" ] ; }
if ( typeof(COORDADDR) == "undefined" ) { COORDADDR = [ "sdbserver1:11810" ] }
if ( typeof(CURSUB) == "undefined" ) { CURSUB = 2 ; }
if ( typeof(ACTIVE) == "undefined" ) { ACTIVE = false ; }执行分裂操作
$ sh split.sh
集群合并
选择集群中的任意一台主机,执行合并操作
$ sh merge.sh
通过 SDB Shell 检查节点间数据是否一致
> db.snapshot(SDB_SNAP_HEALTH, {}, {NodeName: null, IsPrimary: null, CompleteLSN: null})
对比主备节点间字段 CompleteLSN 的值,如果保持一致则说明节点间数据一致
...
{
"NodeName": "sdbserver1:11820",
"IsPrimary": true,
"CompleteLSN": 80148
}
{
"NodeName": "sdbserver2:11820",
"IsPrimary": false,
"CompleteLSN": 80148
}
{
"NodeName": "sdbserver3:11820",
"IsPrimary": false,
"CompleteLSN": 80148
}
...
Note:
如果主备节点间字段 CompleteLSN 的值不一致,用户需等待片刻,待节点数据同步后再次检查节点数据是否一致。
关闭自动全量同步
> db.updateConf({dataerrorop: 2})集群信息初始化
集群信息初始化操作用于将主节点分配至主中心,以恢复集群初始状态。执行该操作前,用户需转移或删除集群部署信息文件 datacenter_init.info,该文件位于 SequoiaDB 安装目录。
根据数据中心划分子网,主中心为 SUB1,灾备中心为 SUB2
| 子网 | 主机 |
|---|---|
| SUB1 | sdbserver1、sdbserver2 |
| SUB2 | sdbserver3 |
选择 SUB1 的任意一台主机,切换至容灾工具目录
$ cd /opt/sequoiadb/tools/dr_ha
修改配置文件 cluster_opr.js
$ vim cluster_opr.js
修改内容如下:
if ( typeof(SEQPATH) != "string" || SEQPATH.length == 0 ) { SEQPATH = "/opt/sequoiadb/" ; }
if ( typeof(SDBUSERNAME) != "string" ) { SDBUSERNAME = "sdbadmin" ; }
if ( typeof(SDBPASSWD) != "string" ) { SDBPASSWD = "sdbadmin" ; }
if ( typeof(SUB1HOSTS) == "undefined" ) { SUB1HOSTS = [ "sdbserver1", "sdbserver2" ] ; }
if ( typeof(SUB2HOSTS) == "undefined" ) { SUB2HOSTS = [ "sdbserver3" ] ; }
if ( typeof(COORDADDR) == "undefined" ) { COORDADDR = [ "sdbserver1:11810" ] }
if ( typeof(CURSUB) == "undefined" ) { CURSUB = 1 ; }
if ( typeof(CUROPR) == "undefined" ) { CUROPR = "split" ; }
if ( typeof(ACTIVE) == "undefined" ) { ACTIVE = true ; }
if ( typeof(NEEDBROADCASTINITINFO) == "undefined" ) { NEEDBROADCASTINITINFO = false }集群信息初始化
$ sh init.sh
选择 SUB2 的主机,切换至容灾工具目录
$ cd /opt/sequoiadb/tools/dr_ha
修改配置文件 cluster_opr.js
$ vim cluster_opr.js
修改内容如下:
if ( typeof(SEQPATH) != "string" || SEQPATH.length == 0 ) { SEQPATH = "/opt/sequoiadb/" ; }
if ( typeof(SDBUSERNAME) != "string" ) { SDBUSERNAME = "sdbadmin" ; }
if ( typeof(SDBPASSWD) != "string" ) { SDBPASSWD = "sdbadmin" ; }
if ( typeof(SUB1HOSTS) == "undefined" ) { SUB1HOSTS = [ "sdbserver1", "sdbserver2" ] ; }
if ( typeof(SUB2HOSTS) == "undefined" ) { SUB2HOSTS = [ "sdbserver3" ] ; }
if ( typeof(COORDADDR) == "undefined" ) { COORDADDR = [ "sdbserver1:11810" ] }
if ( typeof(CURSUB) == "undefined" ) { CURSUB = 2 ; }
if ( typeof(CUROPR) == "undefined" ) { CUROPR = "split" ; }
if ( typeof(ACTIVE) == "undefined" ) { ACTIVE = false ; }
if ( typeof(NEEDBROADCASTINITINFO) == "undefined" ) { NEEDBROADCASTINITINFO = true }集群信息初始化
$ sh init.sh





