关于 SequoiaDB 
快速入门
安装
基本操作
数据模型
SQL引擎
S3引擎
系统架构
数据库管理
连接器
驱动
参考手册
故障排除
SAC 管控中心
Web服务
版本信息
SequoiaDB 巨杉数据库实现了数据的分布式管理,应用程序可以通过丰富的接口对存储在同一集群中的数据进行灵活访问。但在一些大型的系统中,用户会使用多个 SequoiaDB 集群进行数据存储,并需要同时访问多个集群中的数据,因此 SequoiaDB 提供了多数据源的功能。该功能支持通过同一入口,实现跨集群的数据访问,其架构图如下:
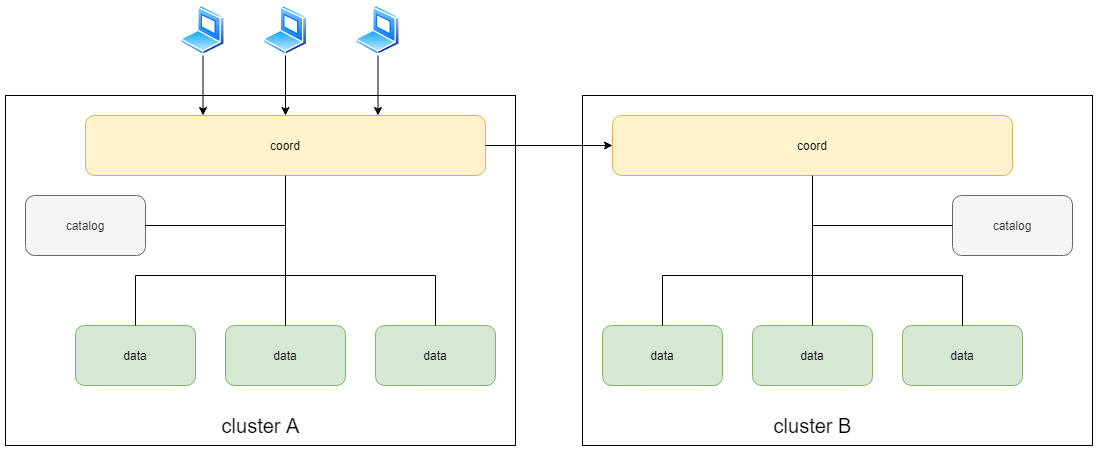
用户在使用数据源功能前,需要先在当前使用的集群中创建数据源,然后在创建集合或集合空间时指定该数据源,使其映射至数据源中对应的集合或集合空间。成功建立映射关系后,用户可以在当前集合中对源数据集合进行数据访问。
当前,数据源支持对集合的基本操作包括 CRUD、 truncate、count、explain、Lob 等,不支持 DDL 操作。用户可通过参数控制报错级别,忽略执行不支持的数据操作时产生的错误信息。
创建名为“datasource”的数据源,并与协调节点地址为 sdbserver1:11810 的集群建立交互通道,该集群的鉴权用户名为“sdbadmin”,用户密码为“sdbadmin”
> db.createDataSource("datasource","sdbserver1:11810","sdbadmin","sdbadmin")
Note:
创建数据源的详细参数说明可参考 createDataSource()。
用户可通过 listDataSources() 或数据源列表查看数据源的元数据信息。
通过 listDataSources()
> db.listDataSources()
通过数据源列表
> db.list(SDB_LIST_DATASOURCES)
Note:
元数据信息字段说明可参考 SYSCAT.SYSDATASOURCES 集合。
用户可以通过创建集合空间或集合时与数据源建立映射,实现跨集群的数据访问。在集合空间上使用数据源时,可以访问被映射集合空间下的所有集合,实现跨集群的多集合数据访问;在集合上使用数据源时,可以实现跨集群的单集合数据访问。
创建集合空间
创建集合空间 sample 并关联数据源 datasource 的集合空间 sample1
> db.createCS("sample",{DataSource:"datasource",Mapping:"sample1"})
Note:
集合空间使用数据源建立映射后,不支持在该集合空间下创建集合。
创建集合
创建集合 sample2.employee 并关联数据源 datasource 的同名集合
> db.sample2.createCL("employee",{DataSource:"datasource"})
创建集合 sample2.employee 并关联数据源 datasource 的集合 sample2.employee1
> db.sample2.createCL("employee",{DataSource:"datasource",Mapping:"employee1"})
创建集合 sample2.employee 并关联数据源 datasource 的集合 sample3.employee1
> db.sample2.createCL("employee",{DataSource:"datasource",Mapping:"sample3.employee1"})
Note:
- 创建集合或集合空间时,如果映射同名集合或集合空间,则不需要指定 Mapping 参数。
- 主集合和分区集合不支持使用数据源。
- 使用了数据源的集合可作为子集合挂载到主集合,但使用了同一数据源的集合在相同主集合下只能挂载一个
查看集合空间信息
通过编目节点查看使用了数据源的集合空间信息
> var cata = new Sdb("sdbserver",11800)
> cata.SYSCAT.SYSCOLLECTIONSPACES.find()
输出结果如下:
{
"_id": {
"$oid": "5ffc2f0072e60c4d9be30c4d"
},
"Name": "sample",
"UniqueID": 1,
"CLUniqueHWM": 4294967296,
"PageSize": 65536,
"LobPageSize": 262144,
"Type": 0,
"DataSourceID": 1,
"Mapping": "sample1",
"Collection": []
}查看集合信息
通过编目快照查看使用了数据源的集合信息
> db.snapshot(SDB_SNAP_CATALOG)
输出结果如下:
{
"_id": {
"$oid": "5ffc313972e60c4d9be30c4f"
},
"Name": "sample2.employee",
"UniqueID": 8589934593,
"Version": 1,
"Attribute": 1,
"AttributeDesc": "Compressed",
"CompressionType": 1,
"CompressionTypeDesc": "lzw",
"CataInfo": [
{
"GroupID": -2147483647,
"GroupName": "DataSource"
}
],
"DataSourceID": 1,
"Mapping": "sample2.employee"
}删除集合空间
删除使用了数据源的集合空间 sample
> db.dropCS("sample")删除集合
删除使用了数据源集合 sample2.employee
> db.sample2.dropCL("employee")
Note:
删除集合或集合空间时,只会删除本地集群的元数据,不会删除数据源中的集合或集合空间。
用户可通过 alter() 修改数据源的名称、地址列表、同步策略等元数据信息。
获取数据源 datasource 的引用
> var ds = db.getDataSource("datasource")
Note:
getDataSource() 用于获取数据源的引用。
将数据源 datasource 更名为“mydata”
> ds.alter({Name:"mydata"})用户可通过 dropDataSource() 删除指定数据源。删除数据源时,需要确保该数据源不关联任何集合空间或集合。
删除名称为“datasource”的数据源
> db.dropDataSource("datasource")
 展开
展开


