在分布式数据库架构中,用户往往采用 PC 服务器与内置盘,取代传统的小型机加外置存储架构。这种 PC 服务器内置盘架构虽然大大降低了硬件的整体成本,但是由于磁盘内置于服务器中,任何服务器硬件故障都有可能导致磁盘数据页写入失败,甚至只写入若干扇区,导致数据丢失或损坏。
在这种情况下,一种典型的做法就是通过软件的方式,将数据库中的数据以同步或异步的方式复制到多台物理设备中,确保任何硬件故障都不会造成整体数据损坏或丢失。
在 SequoiaDB 巨杉数据库中,复制组是指一份数据的多个拷贝,其中每一份数据拷贝被称为数据副本。从系统架构的层面上看,每个数据副本作为一个独立进程存在,也被称为节点。
SequoiaDB 的节点可以以多种角色运行,其中数据节点与编目节点包含用户与系统数据,因此可以通过复制组将其数据在多台物理设备中进行复制拷贝。
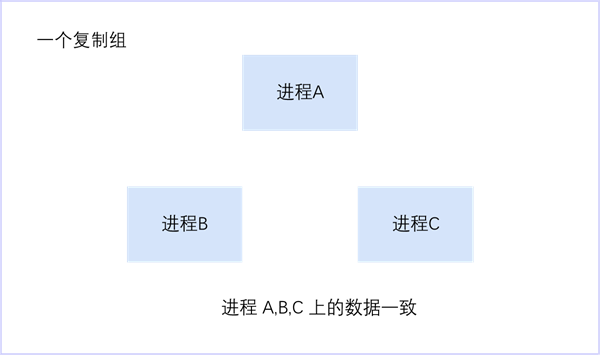
通常情况下,复制组中的每个数据副本需要被存放于不同的物理服务器中,以保证任何物理设备出现故障都不会造成整体影响。通过将数据在多台物理服务器之间进行复制同步,SequoiaDB 可以有效避免单点问题,满足数据库的高可用与灾备能力。
总体来看,SequoiaDB 的复制组功能提供如下特性:
通过学习本章,用户可以了解复制组的原理与应用场景,并熟悉复制组的基本操作。本章主要内容包括:





