序列是可以生成唯一顺序值的对象,通常用于为表中的每一行记录生成唯一的标志符,必须绑定集合中的字段来使用。绑定了序列的字段称为自增字段。
自增字段是使用序列的媒介。在创建自增字段时,系统会为指定的字段创建唯一对应的序列对象,并将序列与字段绑定。一个集合允许拥有多个自增字段。
Note:
- 独立节点不支持自增字段
- 使用主子表时,仅主表自增字段生效,子表自增字段无效
自增字段拥有属性如下:
| 属性名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
| Field | string | - | 自增字段名,必须是可见字符,不能以“$”或空白字符起始;支持嵌套字段;在创建自增字段时指定,指定后不可更改 |
| Increment | int32 | 1 | 序列每次增加的间隔,可以为正整数或负整数;正数表示正序,负数表示逆序;不能为 0 |
| StartValue | int64 | 1 | 序列的起始值,正序时,默认值为 1;逆序时,默认值为 -1 |
| CurrentValue | int64 | - | 序列的当前值,创建时不能指定,可以在序列快照中查看 |
| MinValue | int64 | 1 | 序列的最小值,正序时,默认值为 1;逆序时,默认值为 -263 |
| MaxValue | int64 | 263 -1 | 序列的最大值,正序时,默认值为 263 -1;逆序时,默认值为 -1 |
| CacheSize | int32 | 1000 | 编目节点每次缓存的序列值的数量,取值须大于 0 |
| AcquireSize | int32 | 1000 | 协调节点每次获取的序列值的数量,取值须大于 0,且小于等于 CacheSize |
| Cycled | boolean | false | 序列值达到最大值或最小值时是否允许循环 |
| CycledCount | int32 | - | 序列已循环次数,只读属性,可以在序列快照中查看 |
| Generated | string | "default" | 自增字段生成方式,取值为“always”、“default”、“strict” “always”:表示自增字段总是由服务端生成,忽略客户端的设置 “default”:表示缺省时生成,允许客户端的设置 “strict”:则在允许客户端设置的同时增加类型检测,类型不为数值时报错 |
自增字段的序列值是在编目节点中统一生成,并批量分配给协调节点。编目节点每次会生成若干个序列值,并缓存起来,待缓存分配完,才会再次生成。编目节点缓存序列值的数量取决于序列属性的 CacheSize。类似地,协调节点每次也会请求若干个序列值,待序列值使用完,才会重新请求。协调节点每次获取序列值的数量取决于序列属性的 AcquireSize。
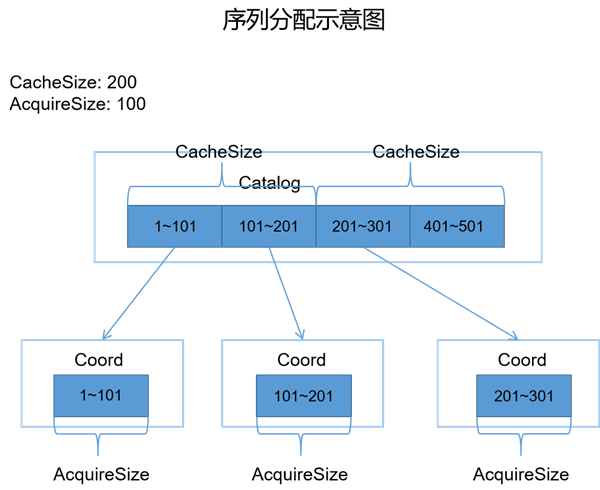
示例中有三个协调节点请求序列值。编目节点 Catalog 每次生成 200 个序列值并缓存起来,而协调节点每次请求 100 个序列值。以 CoordB 为例,当其得到了 101~201 的序列值,那么在 CoordB 上插入记录时,将会为记录的自增字段添加 101、102、103……201 的序列值。在使用完 101~201 全部序列后,CoordB 会再次向 Catalog 请求 100 个新的序列值。而在 Catalog 上,在缓存的序列值消耗完时,也会再次缓存 200 个新的序列值。
因此在这个机制下,自增字段的值默认只保证趋势递增(或递减),但不保证连续分配。如果多个协调节点同时插入数据,在小的区间内,可能会出现后插入的文档的自增字段值比先插入的小,但在大的区间内,数值是递增的。
创建自增字段时,可以在创建集合时指定 AutoIncrement 属性
db.company.createCL("employee", { "AutoIncrement": { "Field": "ID" } } )
Note:
集合的创建可参考 createCL()。
也可以在已存在的集合上使用 createAutoIncrement() 接口来完成
var cl = db.company.createCL("employee")
cl.createAutoIncrement( { "Field": "ID" } )
Note:
如果在已存在数据的集合上创建自增字段,之前的记录依然不会有自增字段值,而创建成功后插入的记录才会出现自增字段值。
通过指定自增字段的选项,可以使自增字段完成逆序生成数值,从指定值开始生成数值等定制化的操作。由于 createCL() 和 createAutoIncrement() 接口中有着相同的自增字段选项,以下均使用 createCL() 进行举例。自增字段有以下选项:
其中必填的选项只有指定字段名的 Field,其它选项均是可选的,下面会根据功能逐一对选项进行介绍。
指定字段
Field 选项指定了集合中字段,用户可以指定首层的字段和嵌套对象中的字段。例如,指定 info 对象中的 ID 字段为自增字段:
var cl = db.company.createCL("employee", { "AutoIncrement": { "Field": "info.ID" } })
cl.insert({ "info": { "name": "Tim", "age": 18 } })
cl.find()
得到以下结果:
{
"_id": {
"$oid": "5cff96cc20c542b37d396f0e"
},
"info": {
"name": "Tim",
"age": 18,
"ID": 1
}
}指定步长和顺序
Increment 选项指定了序列每次增加的间隔,以及序列是正序或逆序,默认为 1。默认生成的序列类似 1、2、3、4、5……,用户也可以指定它为其它的正整数。例如:
db.company.createCL("employee", { "AutoIncrement": { "Field": "ID", "Increment": 2 } })
示例中如果 Increment 为 2,该自增字段生成的序列则会是 1、3、5、7、9……。 Increment 可以为负数,但不能为 0。指定 Increment 为负整数时,自增字段则会递减,比如指定 Increment 为 -2,那么生成的序列将会是 -1、-3、-5、-7、-9……。
指定范围
通过 StartValue,MinValue 和 MaxValue 选项,可以指定自增字段的序列范围。StartValue 表示序列的起始值,MinValue 表示序列的最小值,MaxValue 则表示序列的最大值。正序时,序列默认范围是 1 至有符号 INT64 最大值的区间。即 StartValue = 1,MinValue = 1,MaxValue = 263 -1。而逆序时,序列默认范围是 -1 至有符号 INT64 最小值的区间。即 StartValue = -1, MaxValue = -1, MinValue = -263。
例如,需要指定序列范围为 0 至有符号 INT32 最大值的区间:
db.company.createCL("employee", { "AutoIncrement": { "Field": "ID", "StartValue": 0, "MinValue": 0, "MaxValue": 2147483647 } })
通过 Cycled 选项,还可以控制自增字段超出范围时的行为,默认值为 false。当设置为 true 时,序列到达最大值或最小值,则循环。例如,在正序时如果序列到达 MaxValue,则从 MinValue 开始重新分配。逆序时同理。而设置为 false 时,一旦到达最大值或最小值即会报 "SDB_SEQUENCE_EXCEEDED"错误。
指定序列缓存与请求的数量
通过指定 CacheSize 和 AcquireSize 选项,可以调整序列缓存和请求的数量,从而实现连续递增及性能的调优。自增字段的序列值是先由编目节点批量生成并缓存,然后经协调节点批量请求,才添加到插入的记录上。CacheSize 选项决定了编目节点中每次生成并缓存的序列值的数量。而 AcquireSize 选项决定了协调节点每次获取的序列值的数量。
CacheSize 和 AcquireSize 默认值均为 1000。因此,自增字段的值只保证趋势递增(或递减),但不保证连续分配。如果从多个协调节点插入记录,那生成的序列值可能是1、2、1001、1002、3、1003……如果需要连续分配的序列,可以通过设置 AcquireSize 为 1 来实现。例如,创建一个严格递增的序列:
db.company.createCL("employee", { "AutoIncrement": { "Field": "ID", "AcquireSize": 1 } })
Note:
设置 CacheSize 或 AcquireSize 会直接影响到生成自增字段的性能,建议谨慎调整。
指定序列生成方式
通过指定 Generated 选项可以为序列指定不同的序列生成的方式,不同的生成方式对用户输入自增字段值的处理都不同。以下提供了三种处理方式,分别是"always"、"default" 和 "strict"
"always":自增字段的值总是由系统生成的,忽略用户输入的值。例如:
var cl = db.company.createCL("employee", { "AutoIncrement": { "Field": "ID", "Generated": "always" } })
cl.insert({ "ID": 100 })
cl.find()
得到结果:
{
"_id": {
"$oid": "5cff96cc20c542b37d396f0e"
},
ID: 1
}"default":缺省生成,在用户指定时将使用用户指定的值,否则使用系统生成的值。如上述"always"示例中,将生成方式改为"default",结果中 ID 的值是用户输入的 100,而不是系统生成的 1。
"strict": 严格的缺省生成,与"default"类似,优先使用用户输入的值。"strict"方式在"default"基础上增加了类型的校验。在"strict"方式下,如果用户输入的自增字段类型不是整数,例如 { ID: "string" } 将报参数错误,而在"default"方式下则会成功。
用户在创建自增字段后,也可以根据需要再次修改自增字段的属性。修改属性需使用 setAttributes() 接口。例如,修改自增字段起始值为 1024:
var cl = db.company.createCL( "employee", { "AutoIncrement": { "Field": "ID" } } )
cl.setAttributes( { "AutoIncrement": { "Field": "ID", "StartValue": 1024 } } )
在每次修改时,用户须添加 Field 属性,以标记要修改的字段。自增字段可修改的属性有:
简而言之,除了 Field 外,所有创建时可以指定的选项都是允许更改的。另外允许修改 CurrentValue ,表示序列的当前值。通过调整,正在使用的序列可以从特定数值开始生成下一个值。
Note:
如果客户端在使用中修改过自增字段的值或属性,字段值可能不唯一;如果需要保证修改后值唯一,建议使用唯一索引。
使用编目快照查看自增字段所绑定的序列
例如,查看 company.employee 集合的自增字段属性:
> db.snapshot( SDB_SNAP_CATALOG, { "Name": "company.employee" }, { "AutoIncrement": 1 } )
输出结果如下:
{
"AutoIncrement": [
{
"SequenceName": "SYS_21333102559237_ID_SEQ",
"Field": "ID",
"Generated": "default",
"SequenceID": 4
}
]
}
可以看到,集合的自增字段为 ID,生成方式为"default",绑定了名为"SYS_21333102559237_ID_SEQ"的序列。
使用序列快照查看序列的属性
在步骤 1 中,自增字段绑定了名为"SYS_21333102559237_ID_SEQ"的序列。通过以下命令,用户可以获取序列的具体属性:
> db.snapshot( SDB_SNAP_SEQUENCES, { "Name": "SYS_21333102559237_ID_SEQ" } )
输出结果如下:
{
"AcquireSize": 1000,
"CacheSize": 1000,
"CurrentValue": 5000,
"Cycled": false,
"ID": 4,
"Increment": 10,
"Initial": true,
"Internal": true,
"MaxValue": {
"$numberLong": "9223372036854775807"
},
"MinValue": 1,
"Name": "SYS_21333102559237_ID_SEQ",
"StartValue": 5000,
"Version": 1,
"_id": {
"$oid": "5bd8fcfc8af29ca6ad2a32e8"
}
}通过 dropAutoIncrement() 接口,用户可以实现对自增字段的删除。例如:
> var cl = db.company.createCL("employee", { "AutoIncrement": { "Field": "ID" } })
> cl.dropAutoIncrement("ID")





