在分布式系统中,一致性是指在同一复制组内,节点间保持数据一致的特性。SequoiaDB 巨杉数据库支持不同级别的节点一致性策略,以适配不同的业务场景。
强一致性策略保证在任意时刻节点间的数据均保持一致,适用于对一致性要求高的业务场景。
写所有节点能够保证所有节点的数据一致性,但会降低数据库的高可用性和数据写入性能。发生写操作时,数据库会确保复制组内的所有节点完成同步后,才返回应答给客户端,其逻辑图如下:
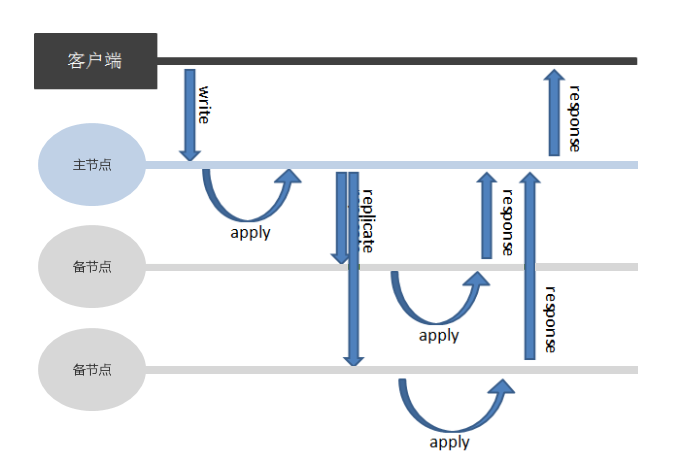
集合的 ReplSize 取值为 0 时表示写所有节点。当组内节点发生故障或异常时,将导致对应的复制组无法写入数据。
该策略能够保证活跃节点的数据一致性。相较于写所有节点,写活跃节点可以提升数据库的高可用性和数据写入性能。发生写操作时,数据库会确保复制组内的活跃节点完成同步后,才返回应答给客户端,其逻辑图如下:
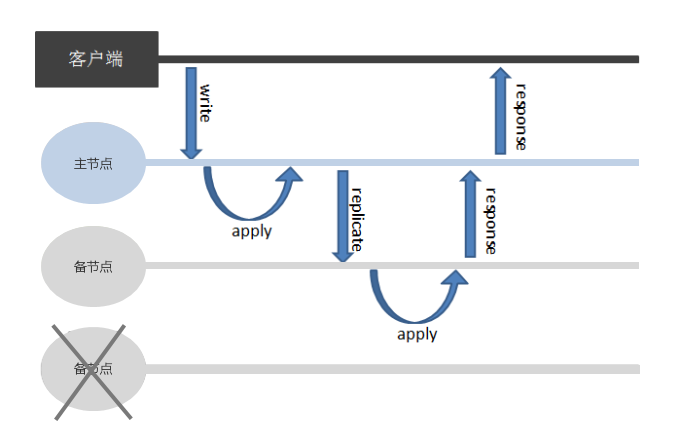
集合的 ReplSize 取值为 -1 时表示写活跃节点。当组内节点故障或异常时,数据仍可写入非故障节点,避免因节点故障或异常导致对应复制组无法写入数据。
最终一致性策略保证在某一时刻节点间的数据可能不一致,但最终会达到一致。相较于强一致性策略,最终一致性策略提升了数据写入效率,适用于对数据库性能要求高的业务场景。
写主节点适用于对数据库性能要求较高的业务,如历史数据查询平台、夜间批量导入数据和白天提供查询业务等。发生写操作时,数据库仅在主节点写入成功后,即返回应答给客户端,其逻辑图如下:
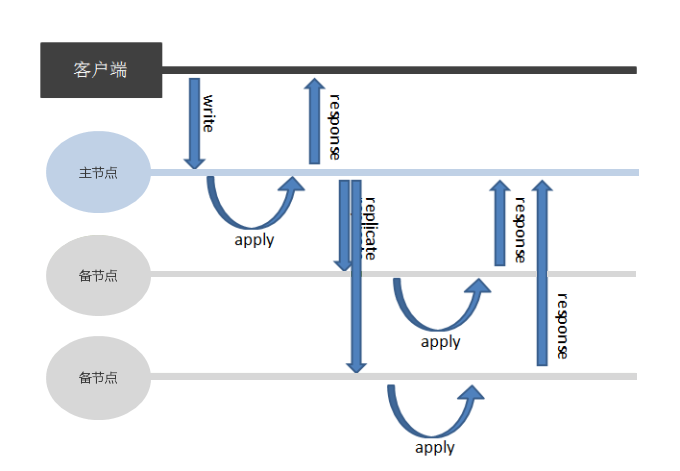
集合的 ReplSize 取值为 1 时表示写主节点,SequoiaDB 默认采用写主节点的最终一致性策略。
写多数派适用于对数据库性能和数据一致性均有要求的业务,如影像内容管理平台、联机交易服务平台等。发生写操作时,数据库会根据 ReplSize 的取值,确保指定数量的节点完成同步后,才返回应答给客户端,其逻辑图如下:
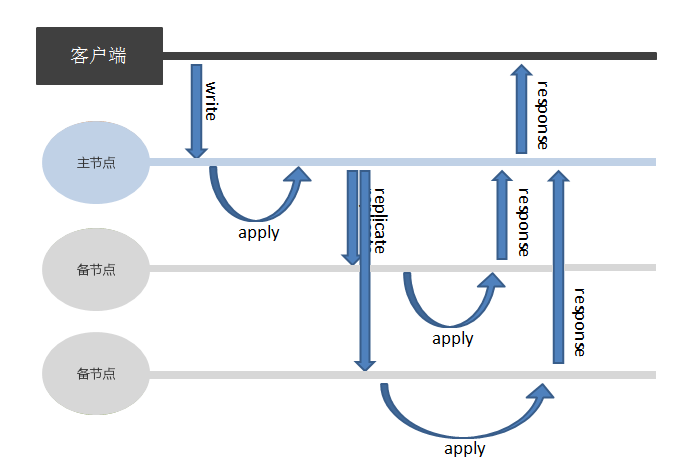
集合的 ReplSize 取值为复制组内节点的半数以上时,表示写多数派。





