SequoiaDB 简介 
快速入门
安装部署
数据库实例
分布式引擎
SAC 管控中心
SequoiaPerf 性能分析工具
参考手册
常见问题及解答(FAQ)
版本信息
本文档主要介绍如何在本地主机采用三副本机制部署 SequoiaDB 巨杉数据库集群。集群模式是 SequoiaDB 巨杉数据库部署的标准模式,具有高可用、容灾、数据分区等能力。
在集群环境下,SequoiaDB 巨杉数据库需要三种角色的节点,分别为:数据节点、编目节点和协调节点。集群模式的最小配置中,每种角色的节点都至少启动一个,才能构成完整的集群模式。
集群模式中客户端或应用程序只需连接协调节点,协调节点会对接收到的请求进行解析,并将请求发送到数据节点进行处理。一个或多个节点组成复制组,复制组间的数据无共享。复制组内各节点采用异步数据复制,以保证数据的最终一致性。
在进行集群模式部署前,用户需要在每台数据库服务器上检查 SequoiaDB 配置服务的状态。
# service sdbcm status
系统提示“sdbcm is running”表示服务正在运行,否则执行如下指令重新配置服务程序:
# service sdbcm start
部署集群模式主要分为以下步骤:
下述操作步骤假设 SequoiaDB 巨杉数据库程序安装在 /opt/sequoiadb 目录下。
Note:
- SequoiaDB 巨杉数据库服务进程全部以 sdbadmin 用户运行,需确保数据库目录都赋予 sdbadmin 读写权限
- 以下操作只须选择任意一台数据库服务器执行即可
创建临时协调节点
切换到 sdbadmin 用户
$ su - sdbadmin
启动 SDB Shell 控制台
$ /opt/sequoiadb/bin/sdb
连接本地集群管理服务进程 sdbcm
> var oma = new Oma("localhost", 11790)创建临时协调节点
> oma.createCoord(18800, "/opt/sequoiadb/database/coord/18800")
Note:
- 18800:协调节点服务端口
/opt/sequoiadb/database/coord/18800:协调节点的数据文件存放路径
启动临时协调节点
> oma.startNode(18800)
创建编目节点组和节点
连接临时协调节点
> var db = new Sdb("localhost",18800)创建编目节点组
> db.createCataRG("sdbserver1", 11800, "/opt/sequoiadb/database/cata/11800")
Note:
sdbserver1:服务器主机名
创建编目节点
> var cataRG = db.getCataRG()
> var node1 = cataRG.createNode("sdbserver2", 11800,"/opt/sequoiadb/database/cata/11800")
> var node2 = cataRG.createNode("sdbserver3", 11800,"/opt/sequoiadb/database/cata/11800")启动编目节点
> node1.start() > node2.start()
创建数据节点组和节点
创建数据节点组
> var dataRG = db.createRG("datagroup")创建数据节点
> dataRG.createNode("sdbserver1", 11820, "/opt/sequoiadb/database/data/11820")
> dataRG.createNode("sdbserver2", 11820, "/opt/sequoiadb/database/data/11820")
> dataRG.createNode("sdbserver3", 11820, "/opt/sequoiadb/database/data/11820")启动数据节点组
> dataRG.start()
创建协调节点组和节点
创建协调节点组
> var coordRG = db.createCoordRG()
创建协调节点
> coordRG.createNode("sdbserver1", 11810, "/opt/sequoiadb/database/coord/11810")
> coordRG.createNode("sdbserver2", 11810, "/opt/sequoiadb/database/coord/11810")
> coordRG.createNode("sdbserver3", 11810, "/opt/sequoiadb/database/coord/11810")启动协调节点组:
> coordRG.start()
删除临时协调节点
连接本地集群管理服务进程 sdbcm
> var oma = new Oma("localhost", 11790)删除临时协调节点
> oma.removeCoord(18800)
如果用户采用高可用与容灾部署方案,在集群部署完成后需按数据中心手动划分位置集,便于后续的灾难恢复。在多中心的部署方案中,为保证数据传输效率,用户需关闭自动全量同步功能,以控制 SequoiaDB 集群对网络宽带的占用。下述以同城双中心的部署方案为例,介绍具体操作步骤。
规划各数据中心对应的位置集
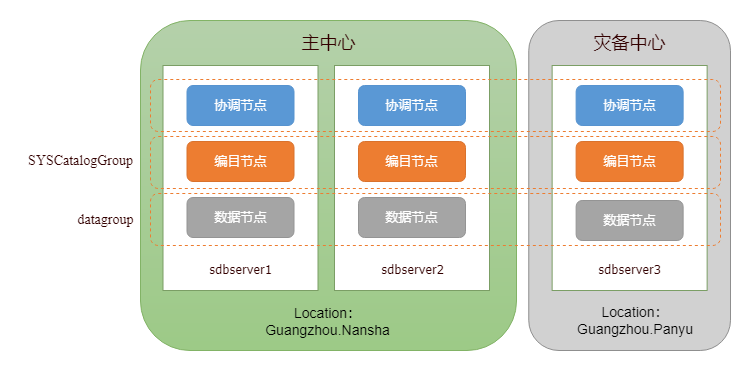
选择主中心的任意一台主机,切换至 SequoiaDB 安装目录并启动 SDB Shell
$ cd /opt/sequoiadb $ ./bin/sdb
连接协调节点
> var db = new Sdb("localhost", 11810)设置编目复制组 SYSCatalogGroup 中各节点的位置集属性
> var cata1 = db.getRG("SYSCatalogGroup").getNode("sdbserver1", 11800)
> cata1.setLocation("Guangzhou.Nansha")
> var cata2 = db.getRG("SYSCatalogGroup").getNode("sdbserver2", 11800)
> cata2.setLocation("Guangzhou.Nansha")
> var cata3 = db.getRG("SYSCatalogGroup").getNode("sdbserver3", 11800)
> cata3.setLocation("Guangzhou.Panyu")
Note:
- 设置位置集属性时,需保证同中心内所有的节点同属一个位置集,同时保证同城的不同中心间具备位置亲和性。
- node.setLocation() 用于设置单个节点的位置信息,domain.setLocation() 用于按域批量设置节点的位置信息,用户可根据实际需求选择操作方式。
设置数据复制组 datagroup 中各节点的位置集属性
> var data1 = db.getRG("datagroup").getNode("sdbserver1", 11820)
> data1.setLocation("Guangzhou.Nansha")
> var data2 = db.getRG("datagroup").getNode("sdbserver2", 11820)
> data2.setLocation("Guangzhou.Nansha")
> var data3 = db.getRG("datagroup").getNode("sdbserver3", 11820)
> data3.setLocation("Guangzhou.Panyu")设置编目复制组和数据复制组的 ActiveLocation
> var cataRG = db.getRG("SYSCatalogGroup")
> cataRG.setActiveLocation("Guangzhou.Nansha")
> var dataRG = db.getRG("datagroup")
> dataRG.setActiveLocation("Guangzhou.Nansha")
Note:
- 如果将某一位置集设置为 ActiveLocation,表示优先从该位置集中选举复制组的主节点。ActiveLocation 需设置为主中心所在的位置集。
- rg.setActiveLocation() 用于设置单个复制组的 ActiveLocation,domain.setActiveLocation() 用于按域批量设置复制组的 ActiveLocation,用户可根据实际需求选择操作方式。
重新选举复制组的主节点,保证各复制组的主节点位于主中心
> cataRG.reelect() > dataRG.reelect()
对于未设置为 ActiveLocation 的位置集,用户需要在其关联的主机中修改节点配置,保证数据传输效率。
逐一修改各主机的配置
$ sed -i "s/AutoStart=.*/AutoStart=false/g" /opt/sequoiadb/conf/sdbcm.conf $ sed -i "s/EnableWatch=.*/EnableWatch=false/g" /opt/sequoiadb/conf/sdbcm.conf
重启各主机的 sdbcm 节点,使配置生效
$ sdbcmtop $ sdbcmart
通过 SDB Shell 检查是否配置成功
> var oma = new Oma("localhost", 11790)
> oma.getOmaConfigs()将参数 dataerrorop 配置为 2,并指定生效范围
> var db = new Sdb("localhost", 11810)
> db.updateConf({"dataerrorop": 2}, {HostName: "sdbserver3"})检查是否配置成功
> db.snapshot(SDB_SNAP_CONFIGS, {}, {NodeName: null, dataerrorop: null}) 展开
展开



