本文档主要介绍在三地五中心的部署方案下,如何应对不同级别的灾难。
当复制组中超过半数节点发生故障,该复制组将无法提供读写服务。针对该情况,用户需进行灾难恢复。如果故障节点未超过半数,用户可通过 startMaintenanceMode() 命令对故障节点开启运维模式,修复并恢复节点数据即可。
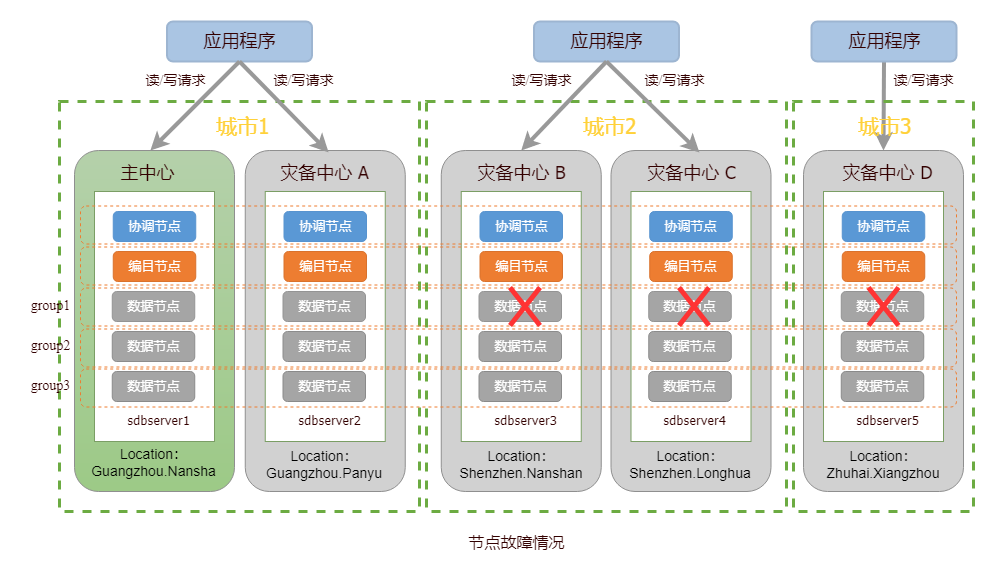
当单个数据中心发生故障,集群仍对外提供读写服务。针对该情况,用户可通过 startMaintenanceMode() 命令对故障中心的节点开启运维模式,修复故障中心并恢复节点数据即可。
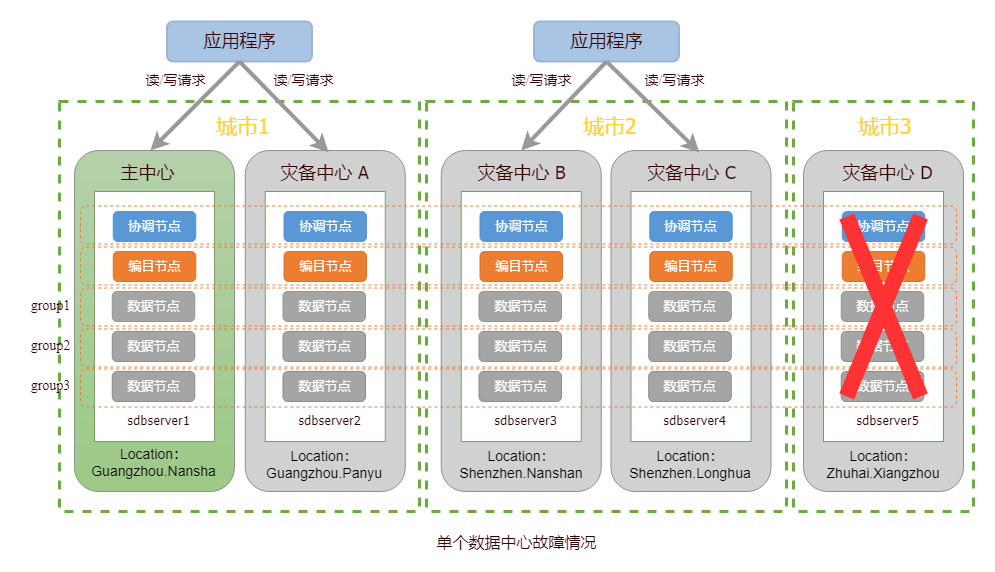
当一个城市发生灾难,导致两个数据中心故障,另外两个城市的数据中心仍可提供读写服务。针对该情况,用户可通过 startMaintenanceMode() 命令对故障中心的节点开启运维模式,修复故障中心并恢复节点数据即可。
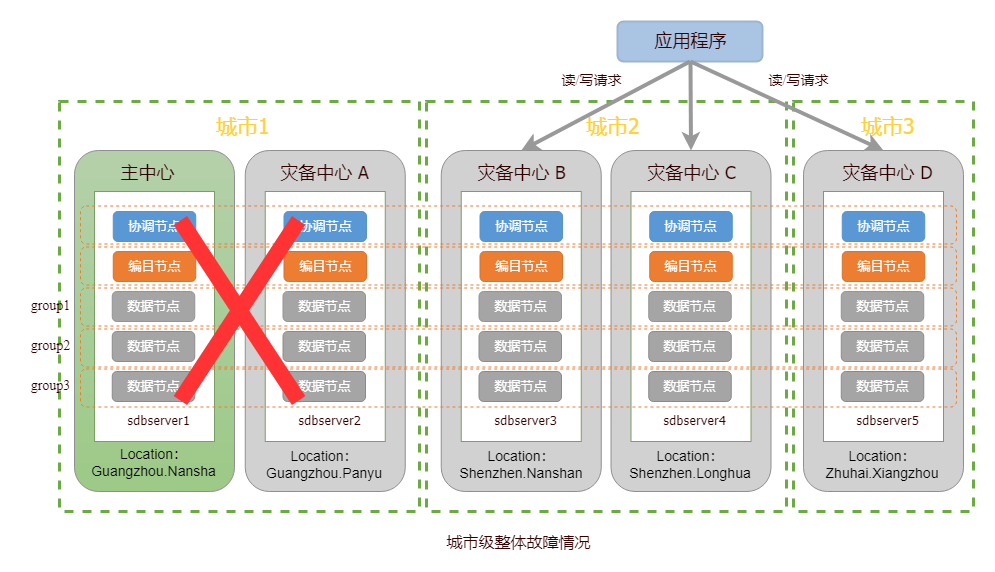
当两个城市发生灾难,集群将失去半数以上的节点,导致无法对外提供读写服务。针对该情况,用户需进行灾难恢复。
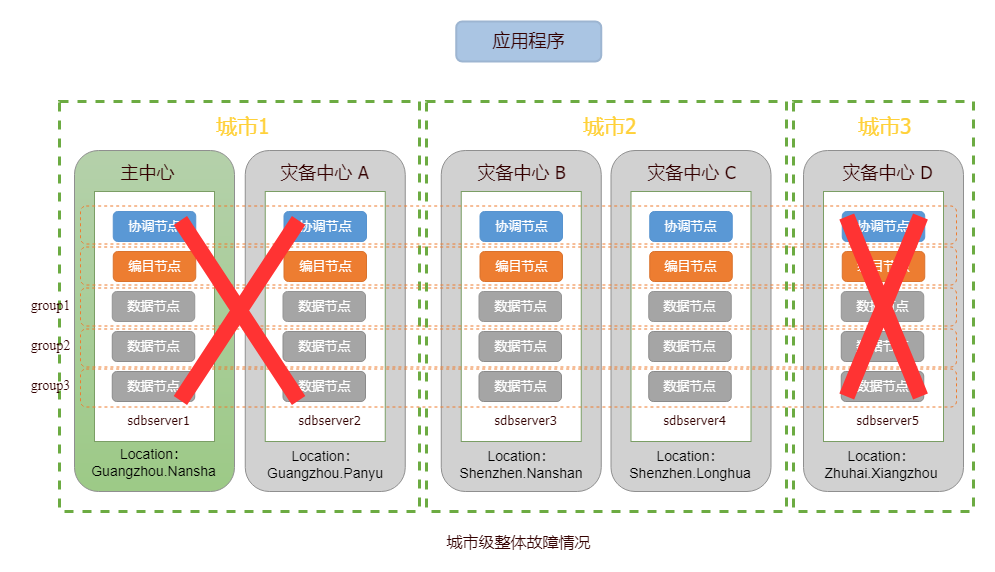
在进行灾难恢复时,用户需根据实际情况选取待恢复的主机,并在该主机上执行后续恢复步骤,实现业务的接管。待恢复主机的选取规则如下:
下述以 SequoiaDB 安装目录 /opt/sequoiadb/、编目节点 11800、协调节点 11810、集群鉴权用户名“sdbadmin”和用户密码“sdbadmin”为例,介绍灾难恢复步骤。
如果集群因数据中心整体故障而导致无法对外提供服务,用户需恢复编目复制组。数据节点故障和网络故障场景可跳过此步骤。
关闭鉴权功能
$ echo "auth=false" >> /opt/sequoiadb/conf/local/11800/sdb.conf
重启编目节点,使配置生效
$ sdbstop -p 11800 $ sdbstart -p 11800
通过 SDB Shell 将当前主机的编目节点升主
> var cata = new Sdb("localhost", 11800)
> cata.forceStepUp()在编目复制组中开启 Critical 模式
> var db = new Sdb("localhost", 11810)
> var cataRG = db.getRG("SYSCatalogGroup")
> cataRG.startCriticalMode({Location: "Guangzhou.Panyu", MinKeepTime: 100, MaxKeepTime: 1000})在各数据复制组中开启 Critical 模式
> var dataRG = db.getRG("group1")
> dataRG.startCriticalMode({Location: "Guangzhou.Panyu", MinKeepTime: 100, MaxKeepTime: 1000})
Note:
参数 MaxKeepTime 表示 Critical 模式的最高运行窗口时间。如果在该时间内故障未修复,系统将强制解除 Critical 模式,集群将回到不可用状态。因此用户需根据实际的故障修复耗时,指定该参数的取值,避免多次执行开启操作。
查看是否成功开启
> db.list(SDB_LIST_GROUPMODES)
输出结果如下,字段 GroupMode 显示为 critical 表示开启成功:
{
"_id": {
"$oid": "6458b62bdfc87b1c4344e16b"
},
"GroupID": 1,
"GroupMode": "critical",
"Properties": [
{
"Location": " Guangzhou.Panyu",
"MinKeepTime": "2023-05-08-18.23.23.445185",
"MaxKeepTime": "2023-05-09-09.23.23.445185",
"UpdateTime": "2023-05-08-16.43.23.445185"
}
]
}
···逐一开启故障节点的自动全量同步功能
$ sed -i "s/dataerrorop=.*/dataerrorop=1/g" /opt/sequoiadb/conf/local/<端口号>/sdb.conf
修复故障
逐一启动故障数据节点
$ sdbstart -p <故障节点端口号>
通过 sdblist 检查各故障数据节点的 GroupID(GID) 和 NodeID(NID) 是否生成,确保故障数据节点注册成功
$ sdblist -l
逐一启动故障编目节点
$ sdbstart -p <故障节点端口号>
检查各主机的节点是否成功启动
$ sdblist -l
检查节点健康检测快照,确定各节点状态恢复为 Normal
通过 SDB Shell 检查 Critical 模式是否解除
> db.list(SDB_LIST_GROUPMODES)
如果字段 GroupMode 显示为 critical 表示未解除,需执行如下命令手动解除:
> var dataRG = db.getRG("group1")
> dataRG.stopCriticalMode()
> var cataRG = db.getRG("SYSCatalogGroup")
> cataRG.stopCriticalMode()
Note:
手动解除 Critical 模式前请确保集群已恢复,否则集群将回到不可用状态。
重新选举各复制组中的主节点,使主节点恢复至故障前所在的数据中心
> dataRG.reelect({Seconds: 60})
> cataRG.reelect({Seconds: 60})关闭非 ActiveLocation 位置集下,所有节点的自动全量同步功能
> db.updateConf({"dataerrorop": 2}, {HostName: ["sdbserver2", "sdbserver3", "sdbserver4", "sdbserver5"]})通过命令行检查鉴权功能的状态
$ cat /opt/sequoiadb/conf/local/11800/sdb.conf
如果参数 auth 的取值为 false ,表示鉴权功能为关闭状态,用户需手动执行如下命令开启鉴权:
$ sed -i "s/auth=.*/auth=true/g" /opt/sequoiadb/conf/local/11800/sdb.conf
重启编目节点,使配置生效
$ sdbstop -p 11800 $ sdbstart -p 11800





