快速入门 
安装
基本操作
数据模型
SQL引擎
系统架构
数据库管理
连接器
驱动
参考手册
故障排除
SAC
版本信息
虽然 Hadoop 占据了大部分的分布式数据分析市场,如今也有其他的平台提供了 Hadoop 平台所没有的许多特性。
Apache 的 Spark 是一个高速的通用集群式计算系统。Spark 是一个可扩展的数据分析平台,该平台集成了原生的内存计算,因此它在使用中相比 Hadoop 的集群存储来说,会有不少的性能优势。
Apache Spark 提供了高级的 Java,Scala 和 Python APIs, 同时还拥有优化的引擎来支持常用的执行图。Spark 还支持多样化的高级工具,其中包括了处理结构化数据和 SQL 的 Spark SQL,处理机器学习的 MLlib,图形处理的 GraphX,还有 SparkStreaming。
虽然 Spark 最初是为了分布式数据集的迭代工作而设计的,但现在 Spark 已经几乎完全拥有了 Hadoop 的所有功能,并且可以基于 Hadoop 文件系统(HDFS)使用。集群模式中,Spark 有几种不同的运行模式,包括了 YARN、Mesos 还有 Standalone。
在集群中,Spark 应用以独立的进程集合的方式运行,并由主程序(driver program)中的 SparkContext 对象进行统一的调度。当需要在集群上运行时,SparkContext 会连接到几个不同类的 ClusterManager(集群管理器)上(Spark 自己的 Standalone/Mesos/YARN), 集群管理器将给各个应用分配资源。连接成功后,Spark 会请求集群各个节点的 Executor(执行器),它是为应用执行计算和存储数据的进程的总称。之后,Spark 会将应用提供的代码(应用已经提交给 SparkContext 的 JAR 或 Python 文件)交给 executor。最后,由 SparkContext 发送 tasks 提供给其执行。
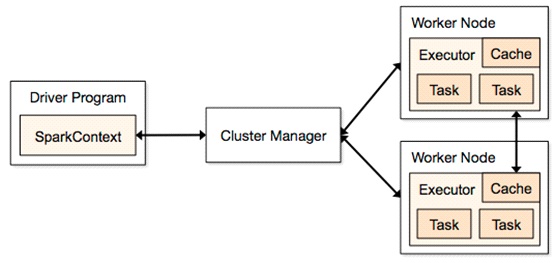
关于这个架构的几点介绍:
 展开
展开


