联邦查询可以将 MySQL 所执行的查询语句透传到远程 SequoiaDB 或 SparkSQL 中,直接获取查询数据,而无需走 MySQL 查询执行引擎。该功能通常用于优化部分 SQL 查询的执行效率,其架构图如下:
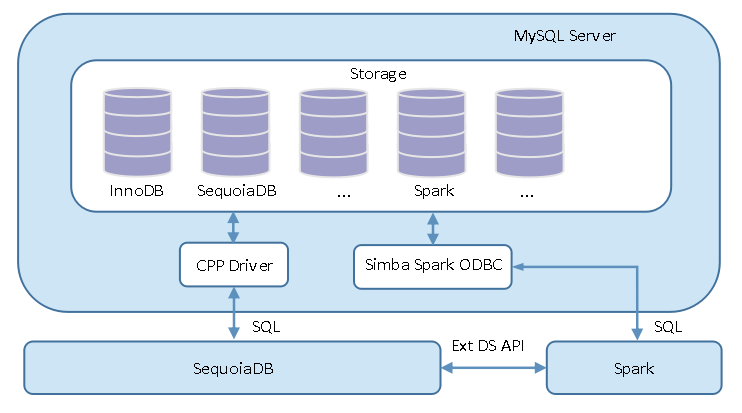
联邦查询根据不同的使用场景,可以分为以下两类:
用户在使用 SequoiaDB 的 SQL 语法进行 SequoiaDB 联邦查询时,需要指定 use_hash(),以支持 HASH Join 算法,优化连接查询的效率。具体操作步骤如下:
准备数据
mysql> CREATE DATABASE company; mysql> USE company; mysql> CREATE TABLE employee(id INT, name VARCHAR(128), age INT); mysql> CREATE TABLE manager(employee_id INT, department TEXT, INDEX id_idx(employee_id)); mysql> INSERT INTO employee VALUES(1, "Jacky", 36); mysql> INSERT INTO employee VALUES(2, "Alice", 18); mysql> INSERT INTO manager VALUES(1, "Wireless Business");
打开联邦查询开关
mysql> set session sequoiadb_sql_push_down = on;
在 SQL 语句中指定 /*+sql_pushdown=sdb*/ 关键词进行联邦查询
mysql> select /*+sql_pushdown=sdb*/ count(t1.employee_id) as cnt from company.manager as t1 inner join company.employee as t2 on t1.employee_id = t2.id /*+ use_hash() */;
Note:
SequoiaDB 联邦查询的 SQL 语法要同时满足 SequoiaDB 的 SQL 法规则和 MySQL 的语法规则。
SparkSQL 联邦查询具体操作步骤如下:
完成 Spark 实例安装部署
安装 unixODBC
对于 CentOS/Red Hat
# yum install unixODBC
对于 Ubuntu
# apt-get install unixodbc
下载 64 位 SimbaSparkODBC
安装 SimbaSparkODBC
对于 CentOS/Red Hat
# yum --nogpgcheck localinstall SimbaSparkODBC-2.6.16.1019-1.x86_64.rpm
对于 Ubuntu
# dpkg -i simbaspark_2.6.16.1019-2_amd64.deb
修改配置文件 <INSTALL_DIR>/Setup/odbc.ini 中[Simba Spark 64-bit]下的 HOST 和 PORT 参数,分别修改为 Spark 实例 thriftserver 的 IP 和监听端口(<INSTALL_DIR>为 SimbaSparkODBC 安装路径,sparkServer 指代 IP 地址,用户可根据实际填写)
# The host name or IP of the Thrift server. HOST=sparkServer # The TCP port Thrift server is listening. PORT=10000
配置环境变量(/opt/simba/spark/ 为 SimbaSparkODBC 的安装路径,用户可根据实际情况修改)
# export LD_LIBRARY_PATH="$LD_LIBRARY_PATH:/opt/simba/spark/lib/64" # export ODBCINI=/opt/simba/spark/Setup/odbc.ini # export ODBCSYSINI=/opt/simba/spark/Setup # export CLOUDERAHIVEINI=/opt/simba/spark/lib/64/simba.sparkodbc.ini
启动 Spark 和 thriftserver
# sbin/start-master.sh # ./sbin/start-thriftserver.sh --master spark://sparkServer:7077
Note:
验证 thriftserver 服务是否启动成功可参考 Spark 连接。
验证 ODBC 是否正常连接 SparkSQL
# isql -v "Simba Spark 64-bit"
在 SequoiaDB 中创建集合 company.employee 和 company.manager,并插入如下记录:
> db.company.employee.insert({id: 1, name: "Jacky", age: 36})
> db.company.employee.insert({id: 2, name: "Alice", age: 18})
> db.company.manager.insert({employee_id: 2, department: "Alice"})在 SparkSQL 中关联 SequoiaDB 的集合空间和集合
spark-sql> CREATE DATABASE company; spark-sql> USE company; spark-sql> CREATE TABLE employee( id INT, name VARCHAR(128), age INT ) USING com.sequoiadb.spark OPTIONS ( host 'localhost:11810', collectionspace 'company', collection 'employee'); spark-sql> CREATE TABLE manager( employee_id INT, department VARCHAR(12) ) USING com.sequoiadb.spark OPTIONS ( host 'localhost:11810', collectionspace 'company', collection 'manager');
设置并打开联邦查询开关(spark_odbc_ini_path 为 SimbaSparkODBC odbc.ini 所在路径,用户可根据实际情况修改)
mysql> set global spark_odbc_ini_path="/opt/simba/spark/Setup"; mysql> set session sequoiadb_sql_push_down = on;
在 MySQL 中指定关键词 /*+sql_pushdown=spark*/ 进行联邦
mysql> select /*+sql_pushdown=spark*/ count(t1.employee_id) as cnt from company.manager as t1 inner join company.employee as t2 on t1.employee_id = t2.id;
Note:
SparkSQL 联邦查询的 SQL 语法要同时满足 SparkSQL 的语法规则和 MySQL 的语法规则。
sequoiadb_sql_pushdown
该参数可以配置是否开启联邦查询功能。
spark_data_source_name
该参数可以配置 SparkSQL 联邦查询时,Spark ODBC 的 DSN(Data Source 名称)。
spark_debug_log
该参数可以配置是否开启 SparkSQL 联邦查询的调试日志。
spark_execute_only_in_mysql
该参数可以配置 SparkSQL 联邦查询时,DQL/DML/DDL 语句只在 MySQL 执行,不会下压到 SparkSQL 执行。
spark_odbc_ini_path
该参数可以配置 SparkSQL 联邦查询时,Spark ODBC 配置文件路径。





