本文档将介绍如何采用三副本机制部署 SequoiaDB 巨杉数据库同城双中心灾备集群,“同城双中心”即主数据中心和同城灾备中心。这种模式下,同城的两个数据中心互联互通,如果一个数据中心发生故障或灾难,另外一个数据中心可以正常运行并对关键业务或全部业务实现接管。
同城双中心灾备架构如图,其中两个副本在主中心,一个副本在灾备中心:
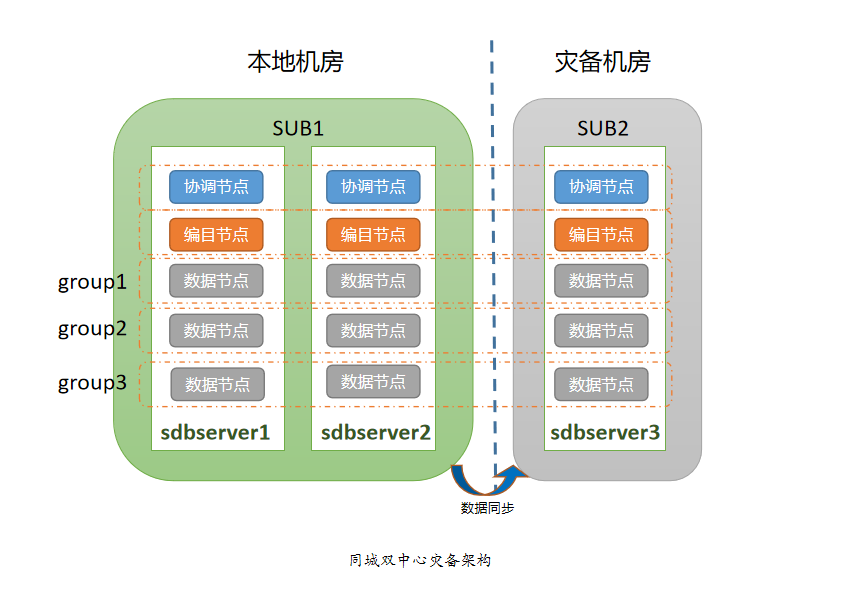
因为同城灾备网络的带宽有限,需要严格控制 SequoiaDB 集群对同城带宽的占用,阻止数据节点在异常终止后进行自动全量同步。用户应设置 sdbcm 节点参数 AutoStart=FALSE 和 EnableWatch=FALSE,并设置每个数据节点参数 dataerrorop=2。
在数据同步方面,应采用 SequoiaDB 提供的节点强一致性功能,当数据写入主节点时,数据库会确保节点间的数据都同步完成后才返回,这样即使在主机房发生整体灾难时也能保证数据的完整性与安全性。
根据 SequoiaDB 同城灾备集群部署情况,可以划分为两个子网(SUB):
| 子网 | 主机 |
|---|---|
| SUB1 | sdbserver1、sdbserver2 |
| SUB2 | sdbserver3 |
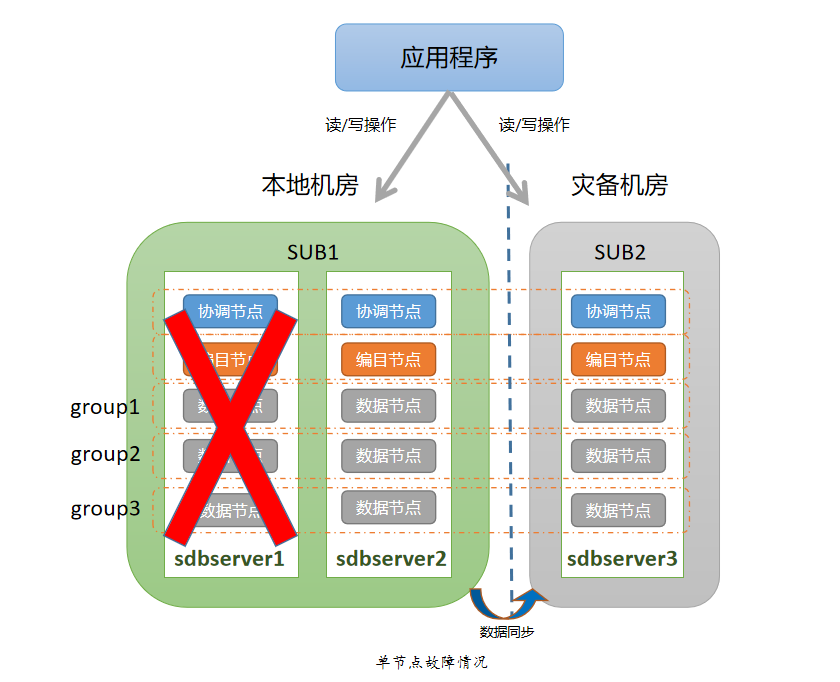
由于采用了三副本高可用架构,个别节点故障情况下,数据组依然可以正常工作。针对个别节点的故障场景,无需采取特别的应对措施,只需要及时修复故障节点,并通过自动数据同步或者人工数据同步的方式去恢复故障节点数据即可。
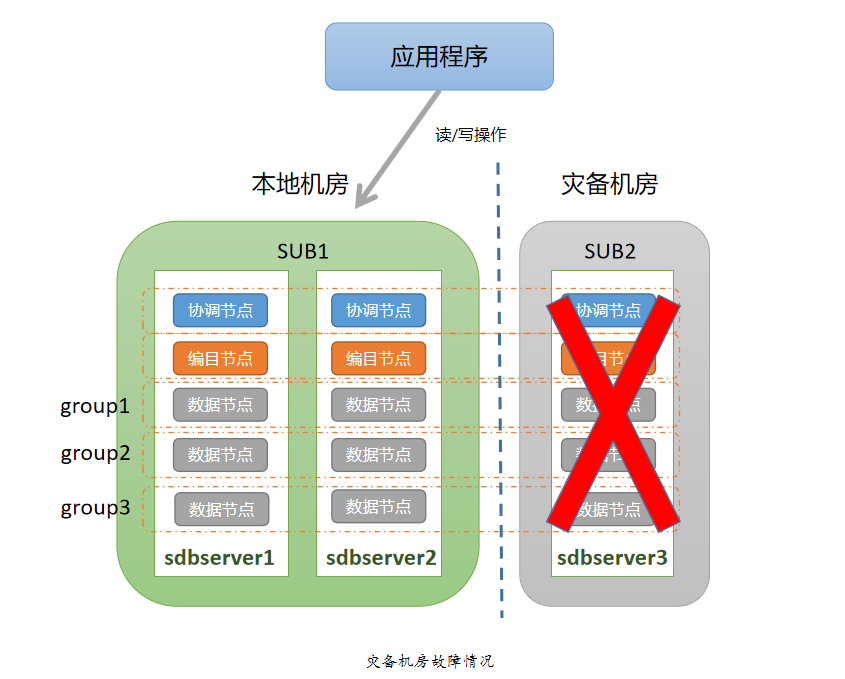
当灾备中心(SUB2)发生故障时,由于每个数据组都有两个副本部署在主中心(SUB1)中,每个数据组存活节点的数量还大于每个数据组的总节点数的 1/2,所以每个数据组仍然能够为应用层提供读写服务。针对灾备中心整体故障的场景,无需采取特别的应对措施,只需要及时修复故障节点,并通过自动数据同步或者人工数据同步的方式去恢复故障节点数据即可。
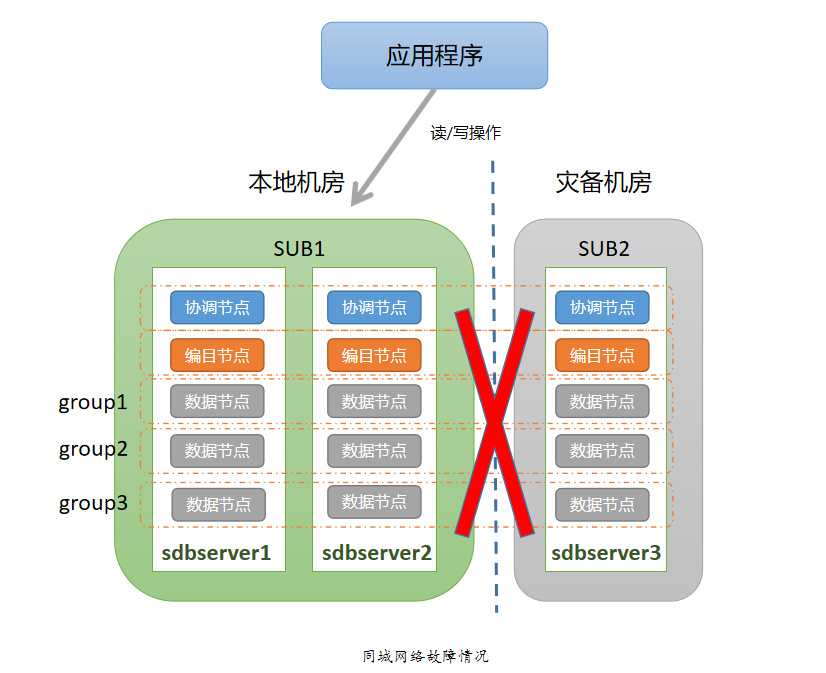
当同城网络出现故障,导致主中心与灾备中心无法进行通信时,由于采用了三副本的架构,应用程序可以通过本地两副本集群进行访问。针对同城网络的故障场景,无需采取特别的应对措施,只需要及时修复网络故障,修复后通过自动数据同步或者人工数据同步的方式去恢复灾备节点的数据即可。
当主中心(SUB1)整体发生故障,整个集群环境将会失去 2/3 的节点,如果从每个数据组来看,相当于每个数据组有两个数据节点出现了故障,存活的节点只剩余一个。这种情况下就需要用到“分裂(split)”和“合并(merge)”工具做一些特殊处理,把灾备中心的集群分裂成单副本集群,这时灾备中心节点可提供读写服务。分裂集群的耗时相对比较短,一般在十分钟内便能完成。具体操作步骤可参考本章中的灾难恢复部分。
SequoiaDB 巨杉数据库对于容灾处理提供了“split/merge”工具。“split”工具的基本工作原理:使某些副本从原有集群中分裂出来,成为一个新的集群,单独提供读写服务;其余副本成为一个新的集群,仅提供读服务。“merge” 工具的基本工作原理:将分裂出去的副本重新合并到原有的集群中,恢复到集群最初的状态。关于工具的更多信息可参考容灾切换合并工具章节。
在 SUB1 和 SUB2 两个子网里分别选择 sdbserver1 和 sdbserver3 作为执行分裂和合并操作的机器。
执行集群分裂和合并操作时,需要知道当前自己所在的子网(SUB)所对应的信息,如当前子网里有哪些机器,每台机器上面分别有哪些节点等。正常情况下,这些信息可以通过访问编目复制组(SYSCatalogGroup)来获取,但当灾难导致主中心整体故障的时候,编目复制组已经无法正常工作;因此需要在集群处于正常状态时获取这些信息,以备灾难发生时使用。
切换至安装路径下的 tools/dr_ha 目录
$ cd /opt/sequoiadb/tools/dr_ha
修改子网 cluster_opr.js 文件配置
SUB1:
if ( typeof(SEQPATH) != "string" || SEQPATH.length == 0 ) { SEQPATH = "/opt/sequoiadb/" ; }
if ( typeof(USERNAME) != "string" ) { USERNAME = "sdbadmin" ; }
if ( typeof(PASSWD) != "string" ) { PASSWD = "sdbadmin" ; }
if ( typeof(SDBUSERNAME) != "string" ) { SDBUSERNAME = "sdbadmin" ; }
if ( typeof(SDBPASSWD) != "string" ) { SDBPASSWD = "sdbadmin" ; }
if ( typeof(SUB1HOSTS) == "undefined" ) { SUB1HOSTS = [ "sdbserver1", "sdbserver2" ] ; }
if ( typeof(SUB2HOSTS) == "undefined" ) { SUB2HOSTS = [ "sdbserver3" ] ; }
if ( typeof(COORDADDR) == "undefined" ) { COORDADDR = [ "sdbserver1:11810" ] }
if ( typeof(CURSUB) == "undefined" ) { CURSUB = 1 ; }
if ( typeof(ACTIVE) == "undefined" ) { ACTIVE = true ; }
SUB2:
if ( typeof(SEQPATH) != "string" || SEQPATH.length == 0 ) { SEQPATH = "/opt/sequoiadb/" ; }
if ( typeof(USERNAME) != "string" ) { USERNAME = "sdbadmin" ; }
if ( typeof(PASSWD) != "string" ) { PASSWD = "sdbadmin" ; }
if ( typeof(SDBUSERNAME) != "string" ) { SDBUSERNAME = "sdbadmin" ; }
if ( typeof(SDBPASSWD) != "string" ) { SDBPASSWD = "sdbadmin" ; }
if ( typeof(SUB1HOSTS) == "undefined" ) { SUB1HOSTS = [ "sdbserver1", "sdbserver2" ] ; }
if ( typeof(SUB2HOSTS) == "undefined" ) { SUB2HOSTS = [ "sdbserver3" ] ; }
if ( typeof(COORDADDR) == "undefined" ) { COORDADDR = [ "sdbserver3:11810" ] }
if ( typeof(CURSUB) == "undefined" ) { CURSUB = 2 ; }
if ( typeof(ACTIVE) == "undefined" ) { ACTIVE = false; }
Note:
初始化时 ACTIVE 的值决定当前子网的权重,SUB1 中应设置 ACTIVE=true,使主节点分布在主中心内,SUB2 中应设置 ACTIVE=false,防止主节点分布在灾备中心内。
在 sdbserver1 上执行 init
$ sh init.sh Begin to check args... Done Begin to check environment... Done Begin to init cluster... Begin to copy init file to cluster hosts Copy init file to sdbserver2 succeed Copy init file to sdbserver3 succeed Done Begin to update catalog and data nodes' config...Done Begin to reload catalog and data nodes' config...Done Begin to reelect all groups...Done Done
Note:
- 执行
init.sh后会生成datacenter_init.info文件,位于 SequoiaDB 安装目录下,如果此文件已存在,需要先将其删除或备份。cluster_opr.js中参数 NEEDBROADCASTINITINFO 默认值为 true,表示将初始化的结果文件分发到集群的所有主机上,所以初始化操作在 SUB1 的 sdbserver1 机器上执行即可。
检查集群情况
sdbserver1:
$ sdblist -l Name SvcName Role PID GID NID PRY GroupName StartTime DBPath sequoiadb 11810 coord 35754 2 5 Y SYSCoord 2019-01-23-19.30.57 /sequoiadb/coord/11810/ sequoiadb 11800 catalog 36518 1 1 Y SYSCatalogGroup 2019-01-23-22.27.20 /sequoiadb/cata/11800/ sequoiadb 11910 data 36517 1002 1006 N group1 2019-01-23-22.27.20 /sequoiadb/group1/11910/ sequoiadb 11920 data 36628 1000 1000 Y group2 2019-01-23-22.30.06 /sequoiadb/group2/11920/ sequoiadb 11930 data 36648 1001 1003 N group3 2019-01-23-22.30.21 /sequoiadb/group3/11930/ Total: 5
sdbserver2:
$ sdblist -l Name SvcName Role PID GID NID PRY GroupName StartTime DBPath sequoiadb 11810 coord 12290 2 6 Y SYSCoord 2019-01-18-07.21.12 /sequoiadb/coord/11810/ sequoiadb 11800 catalog 12305 1 3 N SYSCatalogGroup 2019-01-18-07.21.12 /sequoiadb/cata/11800/ sequoiadb 11910 data 12362 1000 1001 N group1 2019-01-18-07.21.16 /sequoiadb/group1/11910/ sequoiadb 11920 data 12296 1001 1004 Y group2 2019-01-18-07.21.12 /sequoiadb/group2/11920/ sequoiadb 11930 data 12688 1002 1007 Y group3 2019-01-18-08.55.29 /sequoiadb/group3/11930/ Total: 5
sdbserver3:
$ sdblist -l Name SvcName Role PID GID NID PRY GroupName StartTime DBPath sequoiadb 11810 coord 11626 2 7 Y SYSCoord 2019-01-20-02.23.30 /sequoiadb/coord/11810/ sequoiadb 11800 catalog 12419 1 4 N SYSCatalogGroup 2019-01-20-05.01.24 /sequoiadb/cata/11800/ sequoiadb 11910 data 11704 1000 1002 N group1 2019-01-20-02.24.11 /sequoiadb/group1/11910/ sequoiadb 11920 data 11920 1001 1005 N group2 2019-01-20-02.26.05 /sequoiadb/group2/11920/ sequoiadb 11930 data 12416 1002 1008 N group3 2019-01-20-05.01.24 /sequoiadb/group3/11930/ Total: 5
主节点已经全部分布在子网 SUB1 的机器中。
灾难发生时,主中心(SUB1)里的所有机器都不可用,SequoiaDB 集群的三副本中有两副本无法工作。此时需要用“分裂(split)”工具使灾备中心(SUB2)里的一副本脱离原集群,成为具备读写功能的独立集群,以恢复 SequoiaDB 服务。
修改 ACTIVE 参数
在 sdbserver3 机器上修改 cluster_opr.js 中的 ACTIVE 参数为 true
if ( typeof(ACTIVE) == "undefined" ) { ACTIVE = true ; }执行分裂(split)
$ sh split.sh Begin to check args... Done Begin to check environment... Done Begin to split cluster... Stop 11800 succeed in sdbserver3 Start 11800 by standalone succeed in sdbserver3 Change sdbserver3:11800 to standalone succeed Kick out host[sdbserver2] from group[SYSCatalogGroup] Kick out host[sdbserver1] from group[SYSCatalogGroup] Update kicked group[SYSCatalogGroup] to sdbserver3:11800 succeed Kick out host[sdbserver1] from group[group1] Kick out host[sdbserver2] from group[group1] Update kicked group[group1] to sdbserver3:11910 succeed Kick out host[sdbserver1] from group[group2] Kick out host[sdbserver2] from group[group2] Update kicked group[group2] to sdbserver3:11920 succeed Kick out host[sdbserver1] from group[group3] Kick out host[sdbserver2] from group[group3] Update kicked group[group3] to sdbserver3:11930 succeed Kick out host[sdbserver1] from group[SYSCoord] Kick out host[sdbserver2] from group[SYSCoord] Update kicked group[SYSCoord] to sdbserver3:11810 succeed Update sdbserver3:11800 catalog's info succeed Update sdbserver3:11800 catalog's readonly property succeed Update all nodes' catalogaddr to sdbserver3:11803 succeed Restart all nodes succeed in sdbserver3 Restart all host nodes succeed Done
检查灾备中心(SUB2)节点状态
$ sdblist -l Name SvcName Role PID GID NID PRY GroupName StartTime DBPath sequoiadb 11810 coord 13590 - - Y SYSCoord 2019-01-20-09.37.52 /sequoiadb/coord/11810/ sequoiadb 11800 catalog 13587 1 4 Y SYSCatalogGroup 2019-01-20-09.37.52 /sequoiadb/cata/12000/ sequoiadb 11910 data 13578 1001 1005 Y group1 2019-01-20-09.37.52 /sequoiadb/group1/11910/ sequoiadb 11920 data 13581 1002 1008 Y group2 2019-01-20-09.37.52 /sequoiadb/group2/11920/ sequoiadb 11930 data 13584 1000 1002 Y group3 2019-01-20-09.37.52 /sequoiadb/group3/11930/ Total: 5
灾备中心所有节点都是主节点,成为了具备读写功能的单副本 SequoiaDB 集群,可以正常对外提供服务。
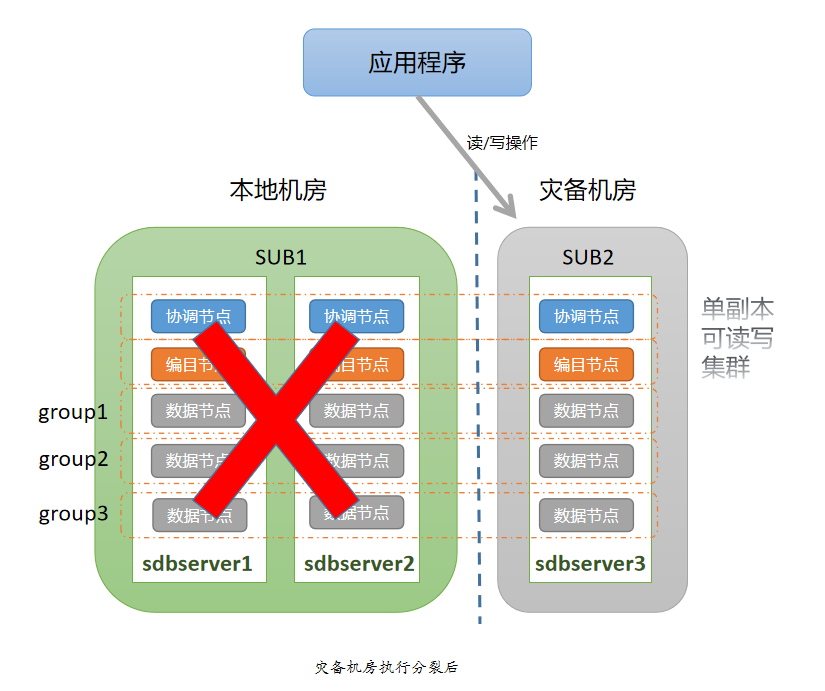
主中心(SUB1)的机器从故障中恢复后,有两种可能的情况:
Note:
主中心(SUB1)的机器恢复正常后,不应手工启动主中心(SUB1)的 SequoiaDB 节点,否则主中心(SUB1)和灾备中心(SUB2)会形成两个独立的可读写 SequoiaDB 集群,如果应用同时连接到 SUB1 和 SUB2,就会出现“脑裂(brain-split)”的情况。
在执行此步骤前,应满足下面的条件:
灾备中心(SUB2)已经成功执行了分裂操作,灾备中心(SUB2)成为具有读写功能的单副本 SequoiaDB 集群。主中心(SUB1)故障已恢复,且 SequoiaDB 数据没有被损坏。
修改 ACTIVE 参数
在 sdbserver1 机器上修改 cluster_opr.js 中的 ACTIVE 参数为 false
if ( typeof(ACTIVE) == "undefined" ) { ACTIVE = false ; }
设置 ACTIVE=false,使分裂后的2副本集群进入“只读”模式,只有灾备中心的单副本集群具有“写”功能,从而避免了“脑裂(brain-split)”的情况。
开启数据节点自动全量同步
如果主中心(SUB1)节点是异常终止的,重新启动节点时必须通过全量同步来恢复数据。数据节点参数设置 dataerrorop=2,会阻止全量同步的发生,导致数据节点无法启动。因此,主中心(SUB1)执行分裂操作之前,需要在所有数据节点的配置文件 sdb.conf 中设置 dataerrorop=1,才能顺利启动数据节点。
执行分裂(split)
$ sh split.sh Begin to check args... Done Begin to check environment... Done Begin to split cluster... Stop 11800 succeed in sdbserver2 Start 11800 by standalone succeed in sdbserver2 Change sdbserver2:11800 to standalone succeed Kick out host[sdbserver3] from group[SYSCatalogGroup] Update kicked group[SYSCatalogGroup] to sdbserver2:11800 succeed Kick out host[sdbserver3] from group[group1] Update kicked group[group1] to sdbserver2:11800 succeed Kick out host[sdbserver3] from group[group2] Update kicked group[group2] to sdbserver2:11800 succeed Kick out host[sdbserver3] from group[group3] Update kicked group[group3] to sdbserver2:11800 succeed Kick out host[sdbserver3] from group[SYSCoord] Update kicked group[SYSCoord] to sdbserver2:11800 succeed Update sdbserver2:11800 catalog's info succeed Update sdbserver2:11800 catalog's readonly property succeed Stop 11800 succeed in sdbserver1 Start 11800 by standalone succeed in sdbserver1 Change sdbserver1:11800 to standalone succeed Kick out host[sdbserver3] from group[SYSCatalogGroup] Update kicked group[SYSCatalogGroup] to sdbserver1:11800 succeed Kick out host[sdbserver3] from group[group1] Update kicked group[group1] to sdbserver1:11800 succeed Kick out host[sdbserver3] from group[group2] Update kicked group[group2] to sdbserver1:11800 succeed Kick out host[sdbserver3] from group[group3] Update kicked group[group3] to sdbserver1:11800 succeed Kick out host[sdbserver3] from group[SYSCoord] Update kicked group[SYSCoord] to sdbserver1:11800 succeed Update sdbserver1:11800 catalog's info succeed Update sdbserver1:11800 catalog's readonly property succeed Update all nodes' catalogaddr to sdbserver1:11803,sdbserver2:11803 succeed Restart all nodes succeed in sdbserver1 Restart all nodes succeed in sdbserver2 Restart all host nodes succeed Done
检查主中心集群状态
主中心(SUB1)完成分裂操作后,由三副本集群变成新的两副本“只读”集群,可以分担一部分业务“读”请求。连接主中心集群,执行“写”操作的命令,如创建集合、插入数据、删除数据等,所有“写”操作应该都执行失败,并提示如下错误信息:
(sdbbp):1 uncaught exception: -287 This cluster is readonly
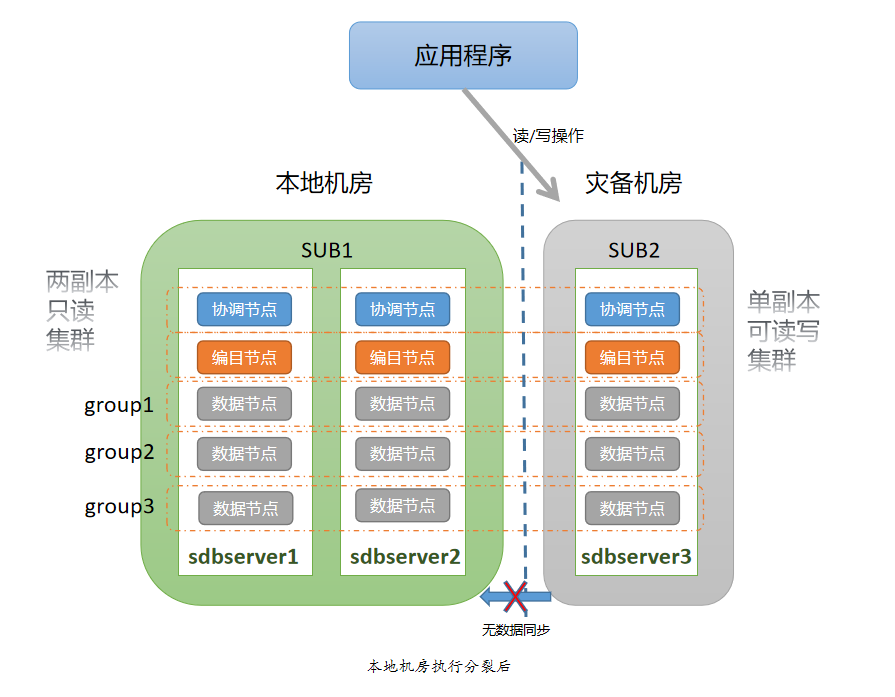
在执行分裂操作之后,主中心(SUB1)和灾备中心(SUB2)是完全独立的两个集群,灾备中心(SUB2)集群具有“读写”功能,会产生新的业务数据,但新的数据不会同步到主中心(SUB1)中。这种情况下,合并成一个集群后,主节点必须落在灾备中心(SUB2)中。所以执行合并操作前,必须保证主中心(SUB1)设置 ACTIVE=false,灾备中心(SUB2)设置 ACTIVE=true。
设置 ACTIVE
SUB1:
if ( typeof(ACTIVE) == "undefined" ) { ACTIVE = false ; }
SUB2:
if ( typeof(ACTIVE) == "undefined" ) { ACTIVE = true ; }灾备中心(SUB2)先执行合并
$ sh merge.sh Begin to check args... Done Begin to check environment... Done Begin to merge cluster... Stop 11800 succeed in sdbserver3 Start 11800 by standalone succeed in sdbserver3 Change sdbserver3:11800 to standalone succeed Restore group[SYSCatalogGroup] to sdbserver3:11800 succeed Restore group[group1] to sdbserver3:11800 succeed Restore group[group2] to sdbserver3:11800 succeed Restore group[group3] to sdbserver3:11800 succeed Restore group[SYSCoord] to sdbserver3:11800 succeed Restore sdbserver3:11800 catalog's info succeed Update sdbserver3:11800 catalog's readonly property succeed Update all nodes' catalogaddr to sdbserver1:11803,sdbserver2:11803,sdbserver3:11803 succeed Restart all nodes succeed in sdbserver3 Restart all host nodes succeed Done
主中心(SUB1)执行合并
$ sh merge.sh Begin to check args... Done Begin to check environment... Done Begin to merge cluster... Stop 11800 succeed in sdbserver2 Start 11800 by standalone succeed in sdbserver2 Change sdbserver2:11800 to standalone succeed Restore group[SYSCatalogGroup] to sdbserver2:11800 succeed Restore group[group1] to sdbserver2:11800 succeed Restore group[group2] to sdbserver2:11800 succeed Restore group[geoup3] to sdbserver2:11800 succeed Restore group[SYSCoord] to sdbserver2:11800 succeed Restore sdbserver2:11800 catalog's info succeed Update sdbserver2:11800 catalog's readonly property succeed Stop 11800 succeed in sdbserver1 Start 11800 by standalone succeed in sdbserver1 Change sdbserver1:11800 to standalone succeed Restore group[SYSCatalogGroup] to sdbserver1:11800 succeed Restore group[group1] to sdbserver1:11800 succeed Restore group[group2] to sdbserver1:11800 succeed Restore group[group3] to sdbserver1:11800 succeed Restore group[SYSCoord] to sdbserver1:11800 succeed Restore sdbserver1:11800 catalog's info succeed Update sdbserver1:11800 catalog's readonly property succeed Update all nodes' catalogaddr to sdbserver1:11803,sdbserver2:11803,sdbserver3:11803 succeed Restart all nodes succeed in sdbserver1 Restart all nodes succeed in sdbserver2 Restart all host nodes succeed Done
检查主节点分布情况
执行合并操作后,确认各复制组的主节点全部分布在灾备中心(SUB2)中
$ sdblist -l Name SvcName Role PID GID NID PRY GroupName StartTime DBPath sequoiadb 11810 coord 15584 2 10 Y SYSCoord 2019-01-20-12.03.50 /sequoiadb/coord/11810/ sequoiadb 11800 catalog 15581 1 4 Y SYSCatalogGroup 2019-01-20-12.03.50 /sequoiadb/cata/11800/ sequoiadb 11910 data 15572 1001 1005 Y group1 2019-01-20-12.03.50 /sequoiadb/group1/11910/ sequoiadb 11920 data 15575 1002 1008 Y group2 2019-01-20-12.03.50 /sequoiadb/group2/11920/ sequoiadb 11930 data 15578 1000 1002 Y group3 2019-01-20-12.03.50 /sequoiadb/group3/11930/ Total: 5
检查数据同步情况
执行合并操作后,主中心(SUB1)需要通过数据同步操作追平灾备中心(SUB2)的数据,此过程由 SequoiaDB 自动触发,不需要人工干预。
可以通过 SequoiaDB 的快照功能检查主中心(SUB1)里的数据节点是否已经完成数据同步并恢复至正常状态。
sdbserver1:
$ sdb "db=Sdb('sdbserver1',11810,'sdbadmin','sdbadmin')"
$ sdb 'db.exec("select * from $SNAPSHOT_DB where NodeName like \"sdbserver1\"")' | grep -E '"NodeName"|Status'
输出结果如下:
"NodeName": "sdbserver1:11800", "ServiceStatus": true, "Status": "Normal", "NodeName": "sdbserver1:11810", "ServiceStatus": true, "Status": "Normal", "NodeName": "sdbserver1:11910", "ServiceStatus": true, "Status": "Normal", "NodeName": "sdbserver1:11920", "ServiceStatus": true, "Status": "Normal", "NodeName": "sdbserver1:11930", "ServiceStatus": true, "Status": "Normal",
sdbserver2:
$ sdb "db=Sdb('sdbserver2',11810,'sdbadmin','sdbadmin')"
$ sdb 'db.exec("select * from $SNAPSHOT_DB where NodeName like \"sdbserver2\"")' | grep -E '"NodeName"|Status'
输出结果如下:
"NodeName": "sdbserver2:11800", "ServiceStatus": true, "Status": "Normal", "NodeName": "sdbserver2:11810", "ServiceStatus": true, "Status": "Normal", "NodeName": "sdbserver2:11910", "ServiceStatus": true, "Status": "Normal", "NodeName": "sdbserver2:11920", "ServiceStatus": true, "Status": "Normal", "NodeName": "sdbserver2:11930", "ServiceStatus": true, "Status": "Normal",
由上面的输出可以看到,在合并操作完成一段时间之后,主中心(SUB1)里所有的节点都已经完成数据同步。
关闭数据节点自动全量同步
当合并操作完成并且主中心(SUB1)和灾备中心(SUB2)的数据追平,后续不再需要数据节点的自动全量同步,因此需要将所有数据节点的 dataerrorop 参数改回最初的设置,即 dataerrorop=2。
连接协调节点,动态刷新节点配置参数
$ sdb "db=Sdb('sdbserver1',11810,'sdbadmin','sdbadmin')"
$ sdb "db.updateConf({dataerrorop:2}, {GroupName:'group1'})"
$ sdb "db.updateConf({dataerrorop:2}, {GroupName:'group2'})"
$ sdb "db.updateConf({dataerrorop:2}, {GroupName:'group3'})"
$ sdb "db.reloadConf()"再次执行初始化(init),恢复集群最初状态
由于合并之后,集群中主节点全部分布在灾备集群(SUB2)中,因此需要再次执行初始化操作,将主节点重新分布到主中心(SUB1)中。
Note:
再次执行初始化操作之前,需要先删除 SequoiaDB 安装目录下的
datacenter_init.info文件,否则执行init.sh会提示如下错误:Already init. If you want to re-init, you should to remove the file: /opt/sequoiadb/datacenter_init.info
主中心(SUB1)设置 ACTIVE=true
if ( typeof(ACTIVE) == "undefined" ) { ACTIVE = true; }灾备中心(SUB2)设置 ACTIVE=false
if ( typeof(ACTIVE) == "undefined" ) { ACTIVE = false; }主中心(SUB1)执行初始化
$ sh init.sh Begin to check args... Done Begin to check environment... Done Begin to init cluster... Begin to copy init file to cluster hosts Copy init file to sdbserver2 succeed Copy init file to sdbserver3 succeed Done Begin to update catalog and data nodes' config...Done Begin to reload catalog and data nodes' config...Done Begin to reelect all groups...Done Done
Note:
cluster_opr.js中参数 NEEDBROADCASTINITINFO 默认值为 true,表示将初始化的结果文件分发到集群的所有主机上,所以初始化操作在 SUB1 的 sdbserver1 机器上执行即可。
检查主节点分布情况
重新初始化之后,确认各复制组的主节点全部分布在主中心(SUB1)中
sdbserver1:
$ sdblist -l Name SvcName Role PID GID NID PRY GroupName StartTime DBPath sequoiadb 11810 coord 40898 2 8 Y SYSCoord 2019-01-24-05.35.42 /sequoiadb/coord/11810/ sequoiadb 11800 catalog 41150 1 1 N SYSCatalogGroup 2019-01-24-05.37.29 /sequoiadb/cata/11800/ sequoiadb 11910 data 40886 1001 1003 N group1 2019-01-24-05.35.42 /sequoiadb/group1/11910/ sequoiadb 11920 data 40889 1002 1006 N group2 2019-01-24-05.35.42 /sequoiadb/group2/11920/ sequoiadb 11930 data 40892 1000 1000 N group3 2019-01-24-05.35.42 /sequoiadb/group3/11930/ Total: 5
sdbserver2:
$ sdblist -l Name SvcName Role PID GID NID PRY GroupName StartTime DBPath sequoiadb 11810 coord 15961 2 9 Y SYSCoord 2019-01-18-16.03.39 /sequoiadb/coord/11810/ sequoiadb 11800 catalog 16208 1 3 Y SYSCatalogGroup 2019-01-18-16.05.46 /sequoiadb/cata/11800/ sequoiadb 11910 data 15949 1001 1004 Y group1 2019-01-18-16.03.39 /sequoiadb/group1/11910/ sequoiadb 11920 data 15952 1002 1007 Y group2 2019-01-18-16.03.39 /sequoiadb/group2/11920/ sequoiadb 11930 data 15955 1000 1001 Y group3 2019-01-18-16.03.40 /sequoiadb/group3/11930/ Total: 5
sdbserver3:
$ sdblist -l Name SvcName Role PID GID NID PRY GroupName StartTime DBPath sequoiadb 11810 coord 15584 2 10 Y SYSCoord 2019-01-20-12.03.50 /sequoiadb/coord/11810/ sequoiadb 11800 catalog 15581 1 4 N SYSCatalogGroup 2019-01-20-12.03.50 /sequoiadb/cata/11800/ sequoiadb 11910 data 15572 1001 1005 N group1 2019-01-20-12.03.50 /sequoiadb/group1/11910/ sequoiadb 11920 data 15575 1002 1008 N group2 2019-01-20-12.03.50 /sequoiadb/group2/11920/ sequoiadb 11930 data 15578 1000 1002 N group3 2019-01-20-12.03.50 /sequoiadb/group3/11930/ Total: 5





